Perussuomalaisten ajatushautomon laatiman selvityksen loppupäätelmä nojaa tarkoitushakuiseen väestörajaukseen, jolla vanhimmat ikäryhmät siivotaan pois tilastoista. Kun tarkasteluun otetaan aikusväestö kokonaisuudessaan, kantaväestön nettovaikutus julkiseen talouteen on raportin omilla luvuilla laskettuna maahanmuuttajia huonompi.
Perussuomalaisten ajatushautomo Suomen Perusta julkaisi ennen pääsiäistä maahanmuuton vaikutuksia julkiseen talouteen käsittelevän raportin Maahanmuutot ja Suomen julkinen talous. Tutkimus pyrkii selvittämään maahanmuuttajien aiheuttamat ”julkisen talouden nettovaikutukset”, eli paljonko jää loppusummaksi kun eri maahanmuuttajaryhmien tuottamasta taloudellisesta hyödystä vähennetään aiheutetut kustannukset.
Aivan alkajaisiksi täytyy kiittää raportin laatinutta Samuli Salmista hänen tekemästään mittavasta työstä. Selvitys lienee tähän mennessä yksityiskohtaisin Suomessa tehty yritys arvioida maahanmuuton kokonaiskustannuksia. Metodologisesti se on varsin läpinäkyvä ja helposti sellaisenkin henkilön arvioitavissa, joka ei ole kvantitatiivisen yhteiskuntatutkimuksen asiantuntija (esim. allekirjoittanut).
Harmi kyllä, tutkimuksen loppupäätelmänä mm. raportin julkistustilaisuudessa esitetty arvio – maahanmuutto kokonaisuutena aiheuttaa Suomelle 700 miljoonan vuosittaiset kustannukset, kun taas kantaväestön nettovaikutus henkeä kohden on lähellä nollaa – on saatu aikaiseksi tilastollisella silmänkääntötempulla.
Ikärajaus kaunistelee suomalaissyntyisten lukuja
Tutkimuksen alkuosassa käsitellään 20–62-vuotiaiden, ulkomailla syntyneiden aiheuttamaa nettovaikutusta henkeä kohden viidessä eri ryhmässä: työlliset, työttömät, opiskelijat, eläkeläiset ja muut. Luvussa 7 tarkastellaan eri maahanmuuttajaryhmien kokonaisvaikutusta ikäryhmässä 7–70-vuotiaat. Jälkimmäisessä tarkastelussa ovat mukana myös toisen polven maahanmuuttajat, eli ne joilla on ainakin yksi ulkomailla syntynyt vanhempi.
Tutkimuksessa käytetyistä ikärajauksista varsinkin 7–70 vuotta on epätavallinen, ja ongelmallinen kahdesta syystä:
Tilastokeskuksen avoimista aineistoista ei ole mahdollisuutta tehdä poimintaa etnisen taustan mukaan eri pääasiallisen toiminnan ryhmiin (opiskelijat, työlliset jne.) kuuluvien määristä näillä ikärajauksilla, eivätkä ne ole muissakaan suomalaisissa tutkimusjulkaisuissa kovin yleisiä. Yleisemmin käytetyn ikärajauksen (vaikkapa 15–64-vuotiaat) soveltaminen tekisi tutkimuksen tuloksista paremmin vertailukelpoisia muihin tilastoihin ja tutkimustietoon.
Varsinainen silmänkääntötemppu piilee kuitenkin siinä, että ikähaitarin katkaiseminen asteikon yläpäästä kaunistelee suomalaistaustaisten nettovaikutusta ulkomaalaistaustaisiin verrattuna dramaattisesti.
Suomessa asuu yli 1,1 miljoonaa yli 62-vuotiasta suomea, ruotsia tai saamea äidinkielenään puhuvaa, kun taas vieraskielisistä vain n. 10 000 kuuluu tähän ikäryhmään. Yli 70-vuotiaiden osalta vastaavat luvut ovat 620 000 ja 4 000. Käytännöllisesti katsoen kaikki yli 70-vuotiaat ovat eläkeläisiä ja raportin lukujen mukaan juuri eläkeläisten nettovaikutus julkiseen talouteen on kaikkein voimakkaimmin negatiivinen.
Eräs painavimmista työperäisen maahanmuuton puolesta esitetyistä argumenteista on, että Suomen väestö vanhenee jatkuvasti ja eläkeläisten määrä suhteessa työikäisiin kasvaa huolestuttavasti. Jättämällä laskuista 620 000 eläkeläistä tämä näkökulma saadaan kätevästi ohitettua, mutta kovin älyllisesti rehellisenä tällaista lähestymistapaa ei voi pitää.
Uusi laskelma perustuu raportin omiin lukuihin
Raportin sivulta 82 löytyy taulukko, jossa on laskettu kymmeneen suurimpaan maahanmuuttajaryhmään (syntymävaltion perusteella) kuuluvien julkisen talouden nettovaikutukset henkeä kohden:
|
Opiskelijat |
Työlliset |
Työttömät |
Eläkeläiset |
Muut |
| Somalia |
–21 208 € |
–2 998 € |
–17 740 € |
–32 609 € |
–15 945 € |
| Irak |
–15 462 € |
–4 174 € |
–20 842 € |
–21 786 € |
–14 944 € |
| Ruotsi |
–14 905 € |
3 954 € |
–20 032 € |
–31 933 € |
–14 228 € |
| Ent. Jugoslavia |
–13 630 € |
765 € |
–17 874 € |
–22 560 € |
–11 698 € |
| Turkki |
–11 953 € |
1 048 € |
–15 974 € |
–18 005 € |
–9 225 € |
| Thaimaa |
–10 913 € |
–2 326 € |
–16 332 € |
–30 125 € |
–8 712 € |
| Ent. Neuvostoliitto |
–12 089 € |
2 191 € |
–17 615 € |
–23 700 € |
–8 443 € |
| Viro |
–12 630 € |
2 309 € |
–18 041 € |
–28 223 € |
–6 612 € |
| Kiina |
–10 473 € |
3 374 € |
–13 710 € |
–26 723 € |
–5 089 € |
| Saksa |
–11 817 € |
8 516 € |
–15 095 € |
–20 904 € |
–4 708 € |
| Kaikki ulkomaat |
–13 465 € |
2 742 € |
–17 594 € |
–26 692 € |
–8 734 € |
| Suomi |
–17 017 € |
5 337 € |
–12 568 € |
–24 254 € |
–11 242 € |
Yhdistin tämän taulukon henkilöä kohden lasketut luvut Tilastokeskuksen avoimiin tietoihin eri ryhmiin kuuluvien määristä siten, että kaikki 15 vuotta täyttäneet otetaan mukaan. Laajensin tarkastelun samalla kaikkiin ulkomaalaisryhmiin ja selvitin, miten suomalaiset kunnat sijoittuisivat suhteessa niihin. Kunnista kerrotaan myös kuntatyyppi tilastollisen kuntaluokituksen mukaan ja perussuomalaisten kannatus viime kunnallisvaaleissa (2012). Näin syntynyt interaktiivinen visualisointi löytyy alta. (Visualisointi ei välttämättä näy oikein kaikilla vanhemmilla selaimilla.)
Haluan vielä erikseen korostaa, että kaikki visualisoinnin tiedot perustuvat perussuomalaisten omassa maahanmuuttoselvityksessä esitettyihin lukuihin (taulukko yllä) ja Tilastokeskuksen avoimiin aineistoihin.
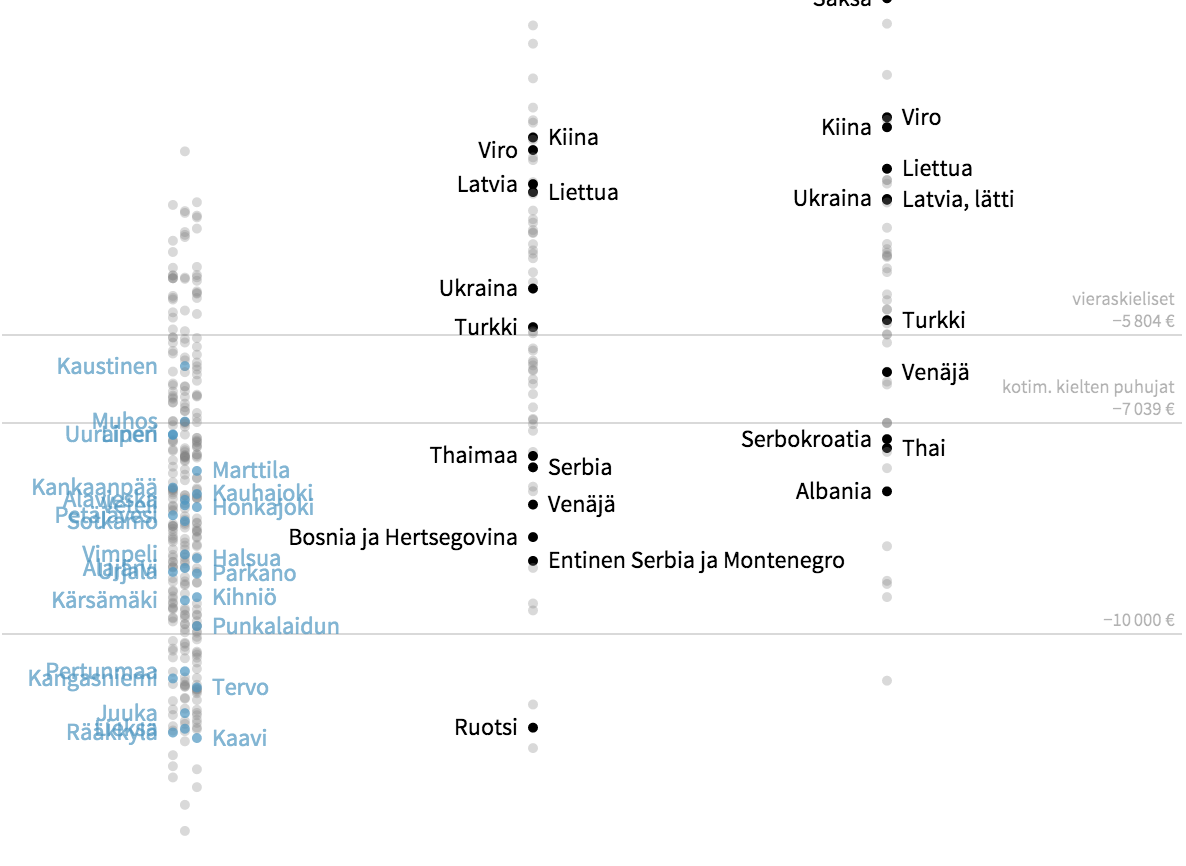
Grafiikassa on sinisellä värillä korostettu ne kunnat, joissa perussuomalaisten kannatus oli kunnallisvaaleissa vähintään 20 %. (Kynnysarvoa voi muuttaa vasemman alakulman säätimellä.) Kansallisuus- ja kieliryhmistä korostettuina näkyvät ne, joille on Suomen Perustan selvityksessä laskettu omat luvut. Muiden ryhmien nettovaikutus on laskettu ”kaikki ulkomaat” -rivin lukujen perusteella.
Kun tarkasteluun otetaan koko 15 vuotta täyttänyt väestö, havaitaan että vieraskielisten vaikutus julkiseen talouteen on perussuomalaisten käyttämällä laskentatavalla negatiivinen (−5 804 € henkeä kohden), mutta kotimaisten kielten puhujien vaikutus on vielä tätäkin negatiivisempi (−7 039 €). Koko eläkeläisväestön ottaminen mukaan tarkasteluun mielivaltaisen 70 vuoden ylärajan soveltamisen sijaan kääntää siis selvityksen alkuperäisen tuloksen päälaelleen: maahanmuuttajien vaikutus julkiseen talouteen on positiivisempi kuin suomalaissyntyisten.
Täsmennys 6.4. klo 16:55: 70 vuoden ikäraja ei ole täysin mielivaltainen, vaan ilmeisesti juontuu käytetystä aineistosta (Tilastokeskuksen yhdistetty työntekijä-työnantaja-aineisto, FLEED), joka sisältää vain 15–70-vuotiaat. Kun aineiston perusteella on kuitenkin pystytty laskemaan nettovaikutus henkeä kohden myös eläkeläisille ja etenkin kun yli 70-vuotiaita maahanmuuttajia Suomessa on vain n. 4 000, olisi jonkinlainen estimaatti voitu ja pitänyt tehdä myös yli 70-vuotiaiden ryhmälle.
Manner-Suomen kunnista vain noin kymmenesosa on nettovaikutukseltaan asukasta kohden vieraskielisten keskiarvoa parempi. Niistä kunnista, joissa perussuomalaisten kannatus oli kunnallisvaaleissa vähintään 20 % ei yksikään yllä vieraskielisten ryhmien keskitasolle ja vain yhden (Kaustinen) nettovaikutus on suomenkielisten keskitasoa positiivisempi.
Onko oikein arvottaa kuntia näin suoraviivaisesti pelkän asukasta kohden lasketun taloudellisen hyödyn mukaan? Pitäisikö eläkeläiset ja perussuomalaisten kannattajat ajaa pois maasta talouslukuja rumentamasta? Ei pitäisi. Ihmisarvoa tai vaikkapa kansallismaiseman arvoa ei mitata rahassa, eikä rahallinen mittari aina huomioi kunnolla kaikkea välineellistäkään hyötyä. Hyvin yksinkertaisena esimerkkinä jälkimmäisestä mainittakoon eläkeläisten apu lastenlasten hoidossa – tällä on hyvin konkreettinen merkitys kansantalouden kannalta, mutta sen täsmällinen hinnoittelu on työlästä, eikä sitä siksi yleensä laskelmissa huomioida.
Myöskään pakolaisia ei Suomeen oteta siksi, että he hyödyttäisivät julkista taloutta, vaan koska on oikein auttaa hädänalaisia. Perhesiteiden kautta maahamme tulevat taas ovat ennen kaikkea jonkun läheisiä ja vasta toissijaisesti työvoimaa ja veronmaksajia. Toki on järkevää pyrkiä hyödyntämään maassa jo asuvien taloudellinen potentiaali, mutta sitä tuskin voimme muuttaa, että juuri maahan saapuneet pakolaiset ovat julkisen talouden näkökulmasta vastakin menoerä. Ja mitä sitten? Niin ovat sairaat ja vanhuksetkin. Ei se tarkoita, että nämä ihmisryhmät pitäisi jättää oman onnensa nojaan.
Selvityksessä käytetty laskentatapa tuottaa absurdeja tuloksia
Työperäisen maahanmuuton kohdalla kysymys taloudellisista vaikutuksista on relevantti, eikä se toki merkityksetön ole muidenkaan maahanmuuttajaryhmien osalta. Harmillisesti on kuitenkin todettava, että perussuomalaisten selvitys ei anna maahanmuuton kustannuksista tai hyödyistä kunnollista kuvaa, koska käytetty laskentatapa on selvästi virheellinen.
Lähes kaikki etniset ryhmät jäävät raportin lukujen mukaan nettovaikutukseltaan selvästi pakkasen puolelle kun myös yli 70-vuotiaat otetaan mukaan laskelmaan. Ainut ryhmä, joka pääsee rimaa hipoen plussalle on Saksan kansalaiset (+12 €). Selvityksen lukujen perusteella voidaan laskea, että 15 vuotta täyttäneiden kotimaisten kielten puhujien yhteenlaskettu nettovaikutus julkiseen talouteen on –30,4 miljardia ja vieraskielisten –1,2 miljardia.
Tämä tarkoittaa sitä, että kaikkien Suomessa asuvien 15 vuotta täyttäneiden yhteenlaskettu nettovaikutus julkiseen talouteen on –31,6 miljardia. Tulos on täysin absurdi ja kertoo, että laskentatapa on pahasti pielessä. Julkisen sektorin alijäämä vuonna 2011 oli todellisuudessa vain 2 miljardia euroa. Käytetty laskentatapa hukkaa siis johonkin melkein 30 miljardia laskelman plussapuolelle kuuluvia eriä (tai liioittelee menoja).
Tästä n. 7 miljardia koostunee laskelmasta tietoisesti pois jätettyjen verojen kuten yhteisö-, kiinteistö-, perintö- ja varainsiirtoverojen osuudesta, mutta ne huomioidenkin laskelmaan jää ammottava aukko. Koko väestön yhteenlasketun nettovaikutuksen pitäisi suunnilleen vastata julkisen talouden sektoritilinpidon loppusummaa (–2 miljardia). Kun otetaan huomioon, että 0–14-vuotiaat tuottavat julkiselle sektorille pääosin menoja, yhteenlasketun nettovaikutuksen pitäisi yli 15-vuotiaiden osalta olla luultavasti jopa jonkin verran plussan puolella. Jos tuloja tai menoja ei pystytä kohdistamaan väestöryhmittäin, ne pitäisi jakaa koko väestön kesken jossain soveliaassa suhteessa, kuten tutkimuksessa on tehty esimerkiksi välillisten verojen ja kollektiivisesti kulutettujen palveluiden (esim. maanpuolustuksen) kohdalla, eikä jättää kokonaan pois, kuten nyt on tehty.
Lisäys 7.4. klo 12:02: Vaikuttaa siltä, että selvityksessä ei ole huomioitu työnantajan eläke- ja sosiaaliturvamaksuja ainakaan 20–62-vuotiaiden henkilöä kohden lasketuissa summissa. Tämä selittäisi noin 17 miljardia tuosta 31,6 miljardin aukosta. Rajaus on todella erikoinen, koska jos maksetut eläkkeet on kuitenkin laskettu mukaan menopuolelle niin totta kai eläkemaksut kuuluvat tulopuolelle. Se, että ne maksaa nimellisesti työnantaja, ei poista sitä että eläkemaksut ovat normaalimääritelmän mukaan osa verokiilaa.
20–62-vuotiaiden maahanmuuttajien ryhmässä työllisiä on selvityksen lukujen mukaan n. 120 000. Raportista ei ilmene, millainen maahanmuuttajien keskimääräinen palkkataso on, mutta tässä nopea laskelma siitä, paljonko työnantajan eläke- ja sosiaaliturvamaksuja tämän suuruiselta ryhmältä kertyisi eri keskimääräisillä kuukausipalkoilla:
• 1 500 €/kk: n. 550 milj. €/v.
• 2 000 €/kk: n. 750 milj. €/v.
• 2 500 €/kk: n. 900 milj. €/v.
• 3 000 €/kk: n. 1,1 mrd €/v.
Väite maahanmuuton 700 miljoonan vuosikuluista julkiselle sektorille näyttää siis perustuvan siihen, että laskelmassa on jätetty osa julkisen sektorin tuloista (eläke- ja sosiaaliturvamaksut) huomioimatta.
Vaikuttaa lähestulkoon siltä, että selvitystä varten on ensin kehitetty laskentatapa, jolla saadaan maahanmuuton kokonaisvaikutus painettua varmasti miinukselle, ja kun on huomattu, että se painaa suomalaissyntyisten loppusumman vielä maahanmuuttajiakin pahemmin pakkaselle, on korjausliikkeenä leikattu vanhimmat ikäluokat tarkastelusta pois. Tuskinpa tutkimuksen laatija sentään aivan näin häikäilemättömän tarkoitushakuisesti on toiminut, mutta kyllä lukujen käsittely pönkittää perussuomalaisten maahanmuuttopoliittista agendaa voimakkaammin kuin mihin niiden objektiivinen tarkastelu mielestäni antaisi aihetta.
Metodologia ja lähteet
Lopuksi vielä muutama sana itse tekemistäni valinnoista ja käytetyistä aineistoista.
Aineistoni ovat perussuomalaisten kannatuslukuja lukuun ottamatta samalta vuodelta (2011) kuin alkuperäisen selvityksen luvut. Kunnallisvaalien 2012 tulos valikoitui aineistoksi vuoden 2011 eduskuntavaalien sijaan, koska kunnallisvaaleissa vaalitulos on helposti saatavissa kunnittain kun taas eduskuntavaaleissa kuntakohtaiset tulokset pitäisi työläästi koostaa äänestysaluekohtaisia tietoja yhdistellen.
Suomen Perustan selvityksessä maahanmuuttotausta on määritelty henkilön tai hänen vanhempiensa syntymämaan mukaan. Tätä tietoa ei Tilastokeskuksen avoimista aineistoista löydy, joten olen käyttänyt visualisoinnissa sen sijaan tietoa pääasiallisesta toiminnasta kansallisuuden ja kielen mukaan. Kansallisuus vastannee siedettävällä tarkkuudella ensimmäisen sukupolven maahanmuuttajan syntymämaata ainakin tuoreemmissa maahanmuuttajaryhmissä ja kieli vuorostaan kertoo likimääräisesti ensimmäisen ja toisen sukupolven maahanmuuttajien kokonaismäärän (sikäli kun kieli voidaan yhdistää yksittäiseen taustamaahan).
Niiden etnisten ryhmien osalta, joille raportissa on laskettu omat luvut (taulukko s. 82), olen käyttänyt näitä lukuja. Muiden osalta laskelman pohjana ovat olleet ”kaikki ulkomaat” -ryhmän luvut. Kielten osalta olen hyödyntänyt tietoa Suomessa asuvien eri kielten puhujien alkuperämaista; esimerkiksi suurin osa Suomen albaniankielisistä on kotoisin entisestä Jugoslaviasta vaikka kieltä puhutaan myös Albaniassa, joten tämän kieliryhmän laskelmassa on käytetty entisen Jugoslavian lukuja. Sen sijaan esimerkiksi arabian puhujat ovat kotoisin useista eri taustamaista, joten tämän ryhmän osalta laskelma perustuu ”kaikki ulkomaat” -ryhmän lukuihin. Tästä säännöstä hieman poiketen ruotsinkielisille on käytetty Suomessa syntyneiden lukuja ja saksankielisille Saksassa syntyneiden. Ruotsin kansalaisille sen sijaan on käytetty Ruotsissa syntyneiden lukuja.
Lähteenä on käytetty Maahanmuutot ja Suomen julkinen talous -raportin lisäksi seuraavia Tilastokeskuksen avoimesta StatFin-tilastotietokannasta löytyviä aineistoja:
Koostetiedosto csv-muodossa löytyy täältä.
Kirjoitin myös jatkoartikkelin aiheesta.















{kind=link}