Kirjoitus on yhteenveto alunperin Twitterissä julkaistusta viestiketjusta.
Opetan XAMKin data-analytiikan koulutusohjelmassa kurssia ”Ajankohtaiset kysymykset ja datavaikuttaminen”, joka käsittelee mm. sitä, miten valtiot, yritykset ja järjestöt käyttävät dataa mielipiteenmuokkauksen ja lobbauksen välineenä. MTK:n viime viikolla julkistama ruokakassivertailu on tyylipuhdas esimerkki tällaisesta datavaikuttamisesta ja toimi kurssillamme erinomaisena case-esimerkkinä. Samalla se osoittaa kuitenkin myös kiinnostavasti, että vaikuttaminen ei aina mene putkeen.
MTK julkisti keskiviikkona 9.2. selvityksen, jossa vertailtiin neljän S-ryhmän ostosdataan perustuvan ruokakassin sekä viidennen, suomalaisiin ravitsemussuosituksiin perustuvan kassin päästöjä niiden sisältämiin ravintoarvoihin suhteutettuna. Viestinnälliseksi kärjeksi oli nostettu, että ravitsemussuositusten mukainen sekasyöjän ruokakassi aiheutti ravintosisältöönsä verrattuna täpärästi pienemmät päästöt kuin kasvispainotteinen, alle 34-vuotiaiden kaupunkilaisten ostosten perusteella muodostettu kassi.
Tähän media tarttui hanakasti. STT:n juttu selvityksestä oli otsikoitu ”Selvitys: Sekasyöjän ruuasta vähiten päästöjä – jos päästöt suhteutetaan ravintoaineiden saantiin”. Jotkut lehdet, esimerkiksi Karjalainen, lyhensivät sen muotoon ”Sekasyöjän ruuasta aiheutuu vähiten päästöjä”.

Selvityksen alkuperäinen, varsin maltillinen löydös paisui matkalla siis melkoisiin mittoihin. MTV3:n uutiset sai sen pyöräytettyä peräti muotoon ”Sekasyönti onkin ilmastoteko”.
Otsikoinnilla on suuri merkitys, sillä moni meistä ei vaivaudu lukemaan otsikkoa pitemmälle varsinkaan silloin, kun se tukee omia ennakokäsityksiä. Pelkän otsikon perusteella innostuivat twiittaamaan niin tavalliset pulliaiset kuin kansanedustajatkin.
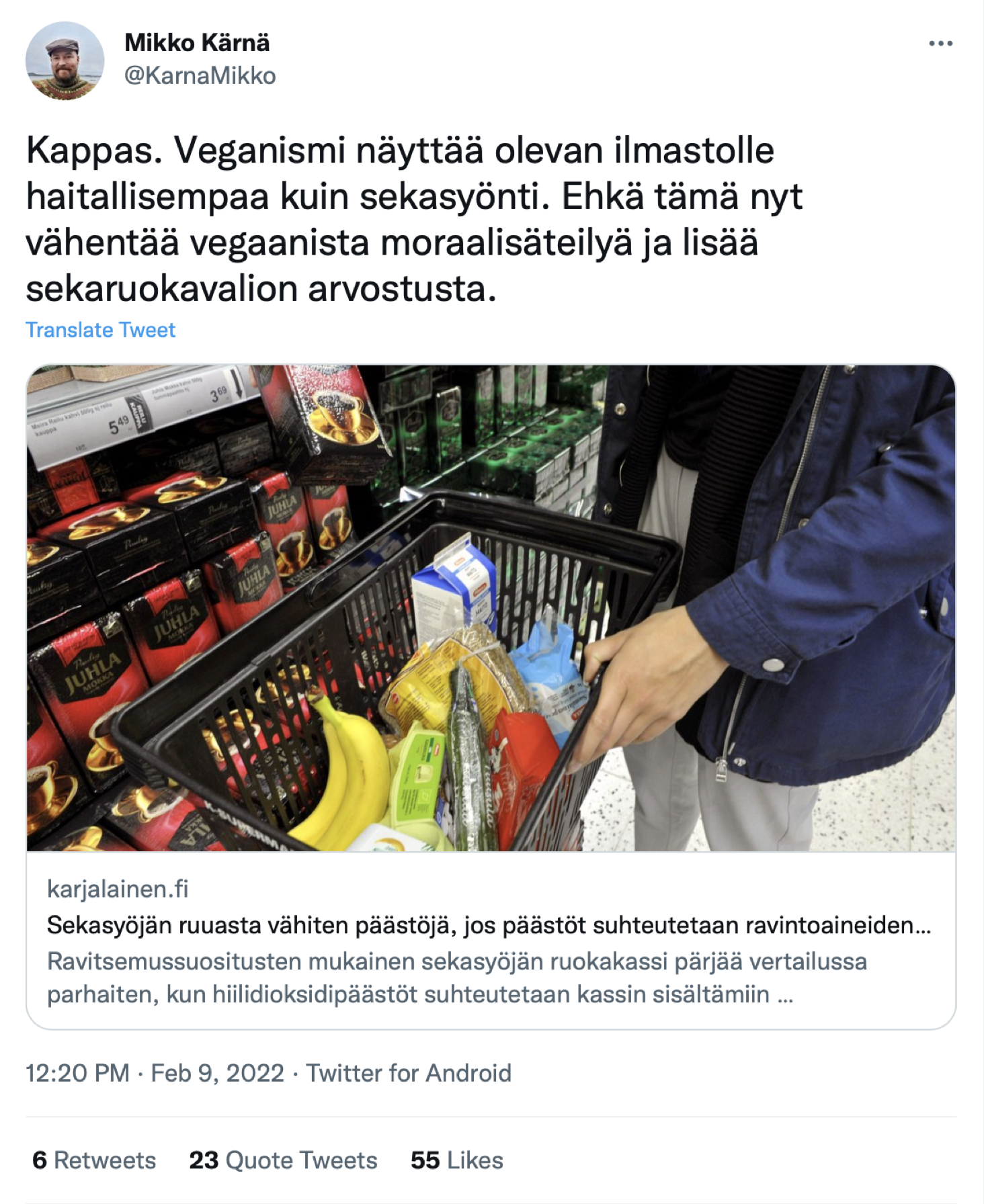
Jos selvityksen materiaalit lukee huolella, selviää kuitenkin, että yksikään vertailussa mukana olleista ruokakasseista ei ollut vegaaninen vaan myös 34-vuotiaiden kaupunkilaisten ostoksiin perustuvassa kassissa oli mukana kalaa ja kananmunia. Tämä huomattiin somessa nopeasti. Media joutuikin pian korjailemaan uutisointia. Varsinaisia oikaisuja ei ole omiin silmiini sattunut, mutta ainakin MTV3 ”tarkensi” uutistaan varsin näkyvästi. STT laati uuden, alkuperäistä selvästi laajemman jatkojutun, jonka monet lehdet julkaisivat. Tämä saattoi olla viestinnällisesti oma maali MTK:lle, sillä alkuperäisen uutisen väitteet kiistävä jatkojuttu tavoitti luultavasti alkuperäistä enemmän lukijoita. Myös somessa huomio oli voittopuolisesti negatiivista.
Korjatustakin uutisoinnista voi kuitenkin jäädä käsitys, että lihaton ja maidoton ruokakassi ei olisi ilmastovaikutuksiltaan lihaa ja maitotuotteita sisältävää, ravitsemussuositusten mukaan koottua kassia parempi. Tämä ei pidä paikkaansa. MTK:n käyttämä tapa laskea ruuan ravintoainetiheyttä on tarkoitushakuinen ja liioittelee eläinperäisten tuotteiden ravintoarvoja. Kuvaan seuraavassa, miten se toimii ja kuinka se tuottaa sopivilla valinnoilla absurdeja tuloksia.
Laskelman on MTK:lle tuottanut Envitecpolis-konsulttiyhtiön asiantuntija Senja Arffman. Se perustuu ilmeisesti alkujaan Arlan tilaamaan työhön, josta muokattiin MTK:n tarpeisiin sopiva alkujaan vuonna 2020, jolloin vertailtiin broileri- ja sushiaterian päästöjä. Jo tuolloin laskelma oli laadittu ilmeisen tarkoitushakuisesti ja se saikin osakseen laajaa kritiikkiä, jota on hyvin koottu yhteen Ruokamysteerit-blogissa. Kriittisiä kommentteja esittivät tuolloin mm. ravitsemusasiantuntija Mikael Fogelholm ja ilmastoasiantuntija Oras Tynkkynen.
Vuoden 2020 indeksi laskettiin vertaamalla annosten sisältämien vitamiinien ja kivennäisaineiden määrää per 100 g ravitsesuosituksen mukaiseen päivän saantisuositukseen. Energiaravintoaineiden osalta vertailukohtana oli se, mikä osuus ravinnosta saatavasta energiasta (E%) tulisi vähintään saada kustakin ravintoaineesta per 1 000 kcal. Kummassakin tapauksessa pudotettiin pois sellaiset ravintoaineet, joiden saanti oli alle 15 % suosituksesta. Raja on valittu mielivaltaisesti ja vaikuttaa tarkoitushakuiselta, sillä se suosii eläinperäisiä tuotteita kasviraaka-aineiden kustannuksella. Lisäksi laskutapaa kritisoitiin siitä, että energiaravintoaineista mukana oli vain proteiini ja välttämättömät rasvahapot. Suomalaiset saavat ruuasta THL:n FinRavinto 2017 -tutkimuksen mukaan liikaa proteiinia, kun taas hiilihydraatin ja kuidun saanti on riittämätöntä.

Uuteen laskelmaan on kriittisen palautteen myötä otettu kuitu mukaan ja huomioitu rasvahappojen saannin osalta myös rasvan laatu (kovat/pehmeät).
MTK:n viime viikolla julkistama laskelma vertaa siis viittä ostoskassia, joista neljä on muodostettu S-ryhmän ostosdatan ja viides ravitsemussuositusten perusteella. Kassien kooksi on vakiotu 15 kg, mutta niiden sisältämä energiamäärä vaihtelee huomattavasti, mikä tuntuu erikoiselta ratkaisulta.
Eri ruokavalioiden ilmastovaikutuksia on aiemmin tutkittu sekä kansainvälisesti (esim. Scarborough et al. 2014) sekä Suomessa, jossa Luke ja Suomen ympäristökeskus tuottivat valtioneuvoston selvitys- ja tutkimustoiminnan (VNTEAS) hankkeena, vuonna 2019 valmistuneen laajan aiheitta käsittelevän RuokaMinimi-tutkimuksen. Tutkimustietoa aiheesta siis on ja sen sanoma on jokseenkin yksiselitteinen. Kuten Luken vanhempi tutkija Juha-Matti Katajajuuri STT:n haastattelussa toteaa: kasvisruoka on yksiselitteisesti ilmastoystävällisin ravinnonlähde. Mitä uutta MTK:n selvitys kysymykseen siis tuo?
Senja Arffmanin mukaan tarkoituksena ei ole ollut vertailla ruokavalioita vaan ostoskäyttäytymistä, mutta tämä tuntuu selittelyltä, varsinkin kun koko tutkimuksen pihvi on ostoskassien sisällön suhteuttaminen ravitsemussuositusten ideaaliarvoihin. Vähintään tutkijan pitäisi pystyä perustelemaan, miksi hänen mentelmänsä tuottaa tieteellisen konsesuksen kanssa selvässä ristiriidassa olevia tuloksia. Tulokset pitäisi myös julkistaa niin, ettei tutkimuskohteesta jää epäselvyyttä.
Todellisuudessa kyse lienee pikemminkin siitä, että MTK haluaa eläintuottajien tukemiseksi hämmentää disinformaatiolla ruuan ympäristövaikutuksista käytävää keskustelua samaan tapaan kuin tupakkateollisuus aikanaan sotki keskustelua tupakan terveyshaitoista. Siksi pidän tarpeellisena nostaa esiin miten tarkoitushakuisella laskentamenetelmällä MTK:n kauppakassivertailu on toteutettu.
Käytetty laskutapa ei ilmene MTK:n omista materiaaleista, mutta Envitecpoliksen blogissa se kuvaillaan – ainakin jollain tarkkuudella.

Ymmärrän blogista löytyvän kuvailun perusteella menetelmän olevan seuraava:
- Verrataan kunkin kassissa olevan ruoka-aineen jokaisen ravintotekijän määrää per 1 000 kcal kyseisen ravintotekijän ravitsemussuositusten mukaiseen minimiravintoaihetiheyteen per 1 000 kcal (Suomalaiset ravitsemussuositukset 2014, Liite 6, s. 51)
- Jos ravintotekijän määrä ruoka-aineessa on vähintään ravitsemussuositusten mukaisen kynnysarvon verran, lisätään prosenttiluku (joka on aina vähintään 100 %) ”ravintoainetiheyspisteisiin”
Ongelmana vain on, että tällä tavoin lasketut ruokakassien pistemäärät ovat n. 50× suurempia kuin tutkimuksen julkistustilaisuuden esittelymateriaalien sivulla 7 kuvatut ravintotiheyspistemäärät!
Kokeilin miettiä muita mahdollisia tulkintoja blogissa kuvaillulle laskentamenetelmälle, mutta mikään keksimäni laskentatapa ei tuota julkistusmateriaalia vastaavia pisteitä, vaan kaikilla eri tavoilla lasketut pisteet ovat huomattavasti suurempia kuin esittelymateriaaleissa mainitut ravintotiheyspisteet.
Koska edellä kuvatulla tavalla lasketut pisteet ovat kuitenkin suunnilleen samassa suhteessa toisiinsa kuin selvityksen materiaaleissa ilmoitetut pisteluvut – tarkoittaen, että esimerkiksi alle 34-vuotiaiden kaupunkilaisten ostoskassin pisteet ovat suuruusluokkaa kaksinkertaiset yli 64-vuotiaiden maaseudulla asuvien ostoskassin pisteisiin – oletan, että selvityksessä käytetty laskentatapa on suunnilleen yllä kuvatun kaltainen ja tuo n. 50-kertainen ero johtuu jostakin pisteille laskemisen jälkeen tehdystä normalisoinnista, jota ei ole menetelmän kuvauksessa mainittu. Näin ollen oletan, että yllä kuvattu menetelmä tuottaa ainakin suhteellisesti oikean suuruisia lukemia, vaikka absoluuttiset pistemäärät poikkeavat huomattavasti ilmoitetuista. (Mikäli tämä oletus on väärä, myös osa kirjoituksen loppuosan johtopäätöksistä saattaa olla virheellisiä.)
Käytetyssä laskentatavassa on ainakin kaksi perustavanlaatuista ongelmaa:
- Elintarvikkeen määrä ostoskassissa ei vaikuta mitenkään sen saamiin pisteisiin.
- Menetelmä suosii elintarvikkeita, joissa on huomattavan suuria määriä yksittäisiä ravintoaineita monipuolisuuden kustannuksella ja ravintoaineen lisääminen parantaa aina tuloksia, vaikka sitä olisi kassissa entuudestaan jo riittävästi.
Koska vertailu perustuu ruoka-aineen ravintoainetiheyteen per 1 000 kcal, ei ole väliä onko sitä kassissa 50 g vai 5 kg – riittää että ruoka-aine on ylipäänsä mukana kassissa. Sen määrä vaikuttaa kuitenkin kassin ilmastopäästöihin, mikä antaa mahdollisuuden pelata luvuilla. Kassithan eivät perustu todellisiin ostoksiin, vaan ”eri ruoka-aineryhmien painottumiseen ostajaprofiileissa” ja ”profiilien suosituimpiin ruokavalintoihin ruoka-aineryhmittäin”. Tämä jättää liikkumavaraa kassin sisällön painottamiselle tarkoitushakuisesti.
(Jo vertailu kasvispainotteisen ja ravitsemussuositusten mukaisen kassin välillä perustuu tarkoitushakuisiin valintoihin, sillä kuten selvityksen taustamateriaaleissa todetaan myös alle 34-vuotiaiden kaupunkilaisten ostoksissa on todellisuudessa mukana paljon liha- ja maitotuotteita.)
Vaikuttaa tarkoitushakuiselta, että vaikka muiden kassien paino on 15 kg, ravitsemussuositusten mukaisen kassin sisältämien elintarvikkeiden kokonaispaino on vain 13,5 kg. Näin kassin ilmastopäästöt on saatu pienemmiksi ilman, että tämä vaikuttaisi ravitsemusarvoihin.
Vertailussa pisteitä saa korkeasta ravintoainetiheydestä, ei monipuolisuudesta. Elintarvike, jonka yhden ravintoaineen tiheys ylittää vertailuarvon moninkertaisesti tuottaa enemmän pisteitä kuin ruoka-aine, jossa monen tiheys jää täpärästi rajan alle. Esimerkiksi juustonaksujen ja perunalastujen ravintoainetiheys vastaa tällä laskutavalla ruisleipää ja vitaminoitu energiajuoma pieksee kalan ja lihan sekä monet vihannekset ja hedelmät. Kahvi ja aromisuola ovat varsinaisia superfoodeja.
Niinpä suunnilleen samaan ravintoainetiheyteen vertailussa mukana olleen lapsiperheen ostoskassin kanssa päästään esim. seuraavalla ”poikamiehen ostoskassilla”:
- herkkusienipizza
- soijanakki
- tonnikalasäilyke
- tumma makaroni
- ranskanleipä
- suklaa–mansikkamuro
- suolapähkinä
- perunalastu
- juustonaksu
- vähärasvainen kermaviili + dippijauhe
- ketsuppi
- hampurilaiskastike
- soijakastike
- sweet & sour -kastike
- sipulirouhe
- valkosipulimurska
- aromisuola
- energiapatukka
- energiajuoma
- kaakaojuoma
- kahvi
- I-olut
On selvää, että yllä kuvattu ruokakassi ei ole ravitsemuksellisesti laadukas. Se sisältää kuitenkin vain vähän eläintuotteita, joten mikäli kassille laskettaisiin myös ilmastopäästöt, se saattaisi saada suunnilleen yhtä hyvän ”CO2-ravintotiheysindeksin” kuin ravitsemussuositusten mukainen kassi.
Koska tutkimuksessa käytettyjä menetelmiä ei ole kuvattu läpinäkyvästi olen saattanut laskea edellä väärin. On kuitenkin selvää, että käytetty menetelmä on altis tietoiselle manipuloinnille ja vaikuttaa siltä, että sitä on myös harjoitettu halutun tuloksen saamiseksi.
MTK on lobbausjärjestö, joka puolustaa jäsentensä etuja tarvittaessa keinoja kaihtamatta (lain puitteissa tietenkin). Siksi heitä on mielestäni turha syyllistää tästä tutkimuksesta. Oma syyttävä sormeni osoittaa ennemminkin mediaan, joka uutisoi siitä kritiikittä. Kun etujärjestö julkaisee selvityksen, joka vaikuttaa haastavan koko vakiintuneen tieteellisen konsensuksen, olisi syytä muistaa Journalistin ohjeiden 12. kohta: ”Tietolähteisiin on suhtauduttava kriittisesti. Erityisen tärkeää se on kiistanalaisissa asioissa, koska tietolähteellä voi olla hyötymis- tai vahingoittamistarkoitus.” Toimittajien pitäisi yllättävän tutkimustuloksen kohdatessaan haastaa tiedontuottajaa enemmän. Miten tulokset on saatu? Miksi ne ovat ristiriidassa aiemman tiedon kanssa?
Mielestäni toimittajien pitäisi olla rohkeampia kyseenalaistamaan myös numerotietoja jos he mielivät toimia ”vallan vahtikoirana”. Olen kirjoittanut tästä aiheesta jutun myös Journalisti-lehteen, otsikolla ”Toimittajat pelkäävät numeroita, kirjoittaa datajournalisti Juuso Koponen”.

















{kind=link}