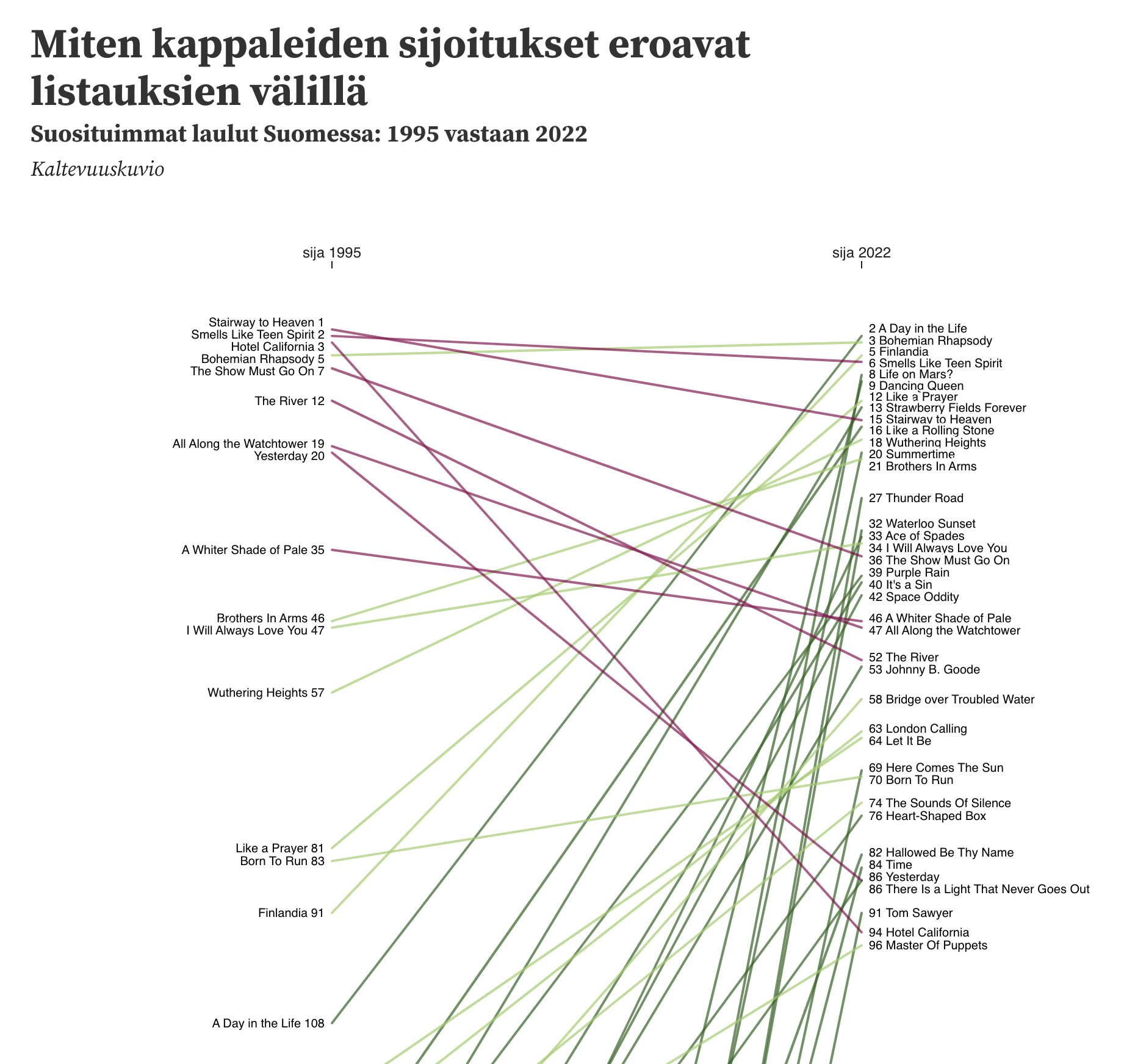
Ovatko ”maailman parhaimmat laulut” suomalaisten mielestä yhä samoja kuin 27 vuotta sitten? Kokeilin visualisointia Observablella ja testasin samalla ”fuzzy match” -toimintoa Pandas-kirjastossa. Aineistona oli Helsingin Sanomien koostama asiantuntijaraadin lista vuodelta 2022 sekä Wikipediassa tallennettu Radio Novan kuulijakyselynä rakennettu listaus vuodelta 1995:
https://observablehq.com/@hjhilden/suosituimmat-laulut-1995-vastaan-2022
Mikä ihmeen Observable?
Observable on Mike Bostockin ja Melody Meckfesselin perustama yritys ja verkkopohjainen ympäristö, jossa luodaan vuorovaikutteisia dokumentteja eli ”muistioita”, englanniksi notebookeja. Bostock tunnetaan suositun D3-JavaScript-kirjaston kehittäjänä, ja D3 onkin keskeinen osa Observablea. Muistio tai notebook on siis tiedosto, joka koostuu soluista. Solut ovat yksikköjä, pieniä laatikoita joihin voi kirjoittaa JavaScript-koodia, HTML:ää sekä tekstiä (jota voi muotoilla Markdown-merkintäkielellä). Ajatus on, että ympäristö auttaa yhdistämään analyysin, visualisoinnin ja julkaisemisen saumattomaksi ja helposti jaettavaksi kokonaisuudeksi.
Perinteisemmän ohjelmointiin verrattuna muistiossa sekä koodi että se mitä sen ajaminen tuottaa näkyy siis samassa dokumentissa. Observablessa jokaisen solun tulos näytetään sen yläpuolella:

Observablella on olemassa runsaasti tutoriaaleja sekä muistioina että videomuodossa ja niihin tutustuminen lienee paras tapa ymmärtää miten ympäristö toimii: https://observablehq.com/tutorials.
Ympäristön dokumentaatio on tietenkin muistion muodossa https://observablehq.com/@observablehq/documentation

Observable muistuttaa Pythonille kehitettyä, suosittua Jupyter-ympäristöä. Jupyterin käyttäjille onkin luotu erityiset työkirjat tutustumista varten: https://observablehq.com/collection/@observablehq/observable-for-jupyter-users
Keskeisimmät erot Jupyteriin ovat siinä, että Observablen solut ajetaan uudestaan automaattisesti, eikä solujen järjestyksellä ole väliä. Tämän takia funktiomäärittelyt voidaan sijoittaa ”piiloon” muistion loppuun, eikä tarvitse muistaa ajaa soluja uudelleen oikeassa järjestyksessä jos tekee muutoksia. Koodi ajetaan siis samalla tavalla kuin funktiot taulukkolaskentaohjemissa kuten Excelissä. Toimintatapaa selitetään tarkemmin tässä muistiossa.
Jokainen solu palauttaa myös ainoastaan yhden arvon – arvot solujen sisällä eivät siis lähtökohtaisesti ole muiden solujen käytettävissä, vaan ne pitää erikseen palauttaa. Toisin kuin Jupyterissa, Observablella ei ole erillistä ydintä eli kerneliä: koodi ajetaan selaimessa. Oletusarvoisesti Observablen muistiot siis asuvat tiedostoina Observablen palvelimella – mutta selaimesi ajaa niissä olevan koodin. Koodia voi myös tuoda vaivattomasti muistiosta eli notebookista toiseen ja erilaisia JavaScript-kirjastoja on helppo käyttää. Muistioita voi myös ”forkata”, eli kopioida uusiksi versioiksi.
Tieteentekijöille Observablen käyttökelpoisuutta voi rajoittaa se seikka, että esimerkiksi kaikille R– tai Python-kirjastoille ei välttämättä ole olemassa suoria tai ainakaan yhtä vakiintuneita ja dokumentoituneita JavaScript-pohjaisia vaihtoehtoja. Sen sijaan se voi olla oiva väline esimerkiksi prototyyppien luomiselle verkkokehittäjille ja datajournalisteille sekä algoritmisen taiteen tekijöille. Se voi myös olla varteenotettava julkaisualusta datajournalistisille projekteille.
Itse tein tähän raakadata datan käsittelyn pääosin Pandas-kirjaston avulla Jupyter-ympäristössä, sillä se on minulle vielä toistaiseksi tutumpi kuin Observable. ”Fuzzy matching” eli sumea vertailu oli helppoa käyttäen difflib-kirjastoa. Ohje löytyi luonnollisestikin StackOverflowista. Kahden DataFramen yhdistäminen indexin perusteella difflibin avulla näyttää tältä:
df2.index = df2.index.map(lambda x: difflib.get_close_matches(x, df1.index)[0]) df1.join(df2)
Tätä ohjetta muokkaamalla sain yhdistettyä kahden eri listan kappaleet nimen perusteella eri vuosilta siitä huolimatta, että niissä oli vaihtelevat kirjoitusasut. En säätänyt algoritmin tarkkuutta, joten se yhdisti aika reippaasti ihmisen näkökulmasta: Abban Don’t Shut Me Down yhdistyi esimerkiksi Pandoran kappaleeseen Don’t You Know. Koska lista tässä tapauksessa oli maltillisen kokoinen, niin oli helpompi siivota nämä käsin pois kuin säätää asetuksia (ja mahdollisesti jättää jokin kappale pois vahingossa!).
Observablen käyttö on tätä kirjoittaessa yksittäisille käyttäjille maksuton, ryhmälisenssit myydään kuukausihinnalla.
Radiomafian, ei Novan kuulijakysely.