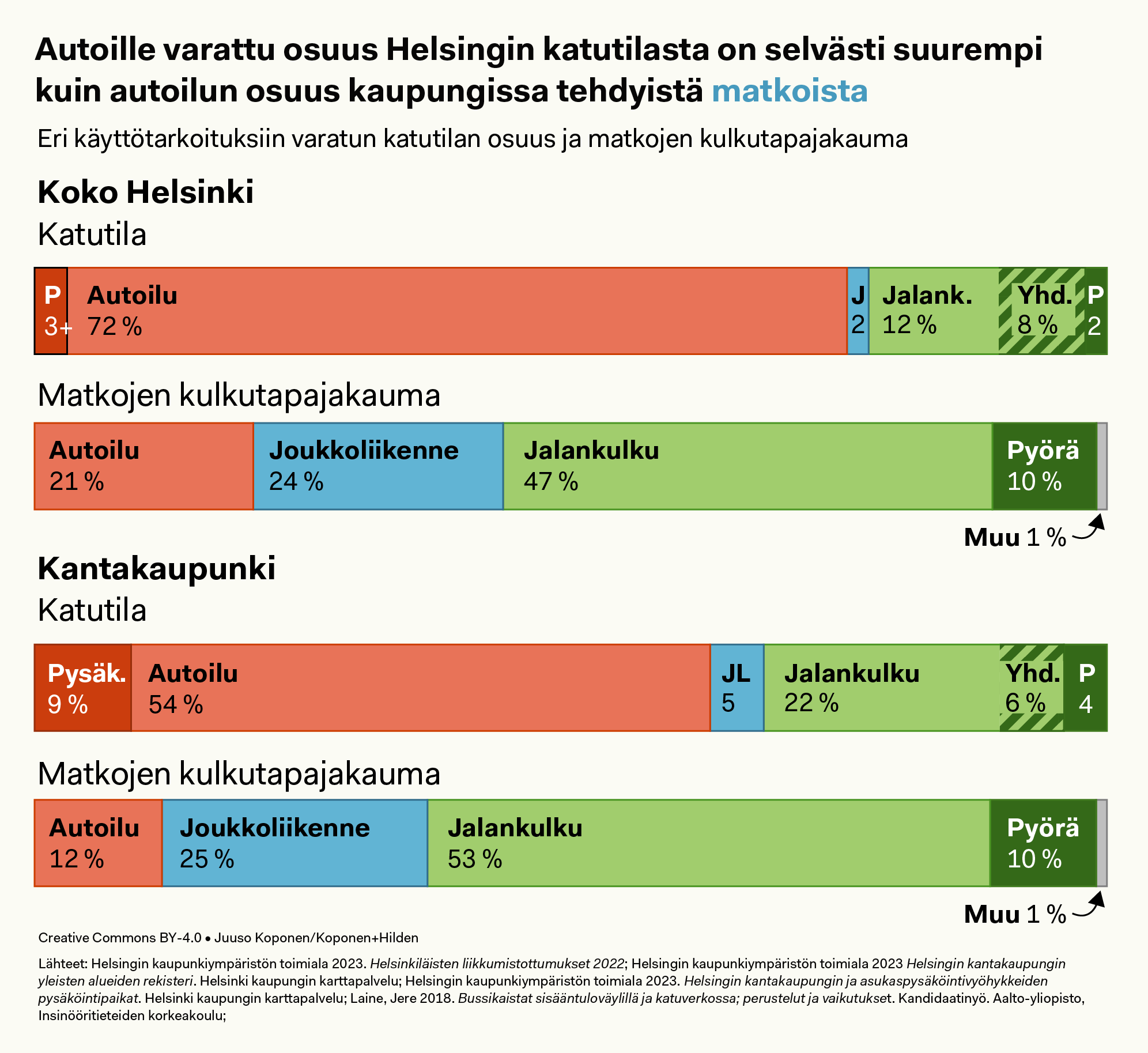
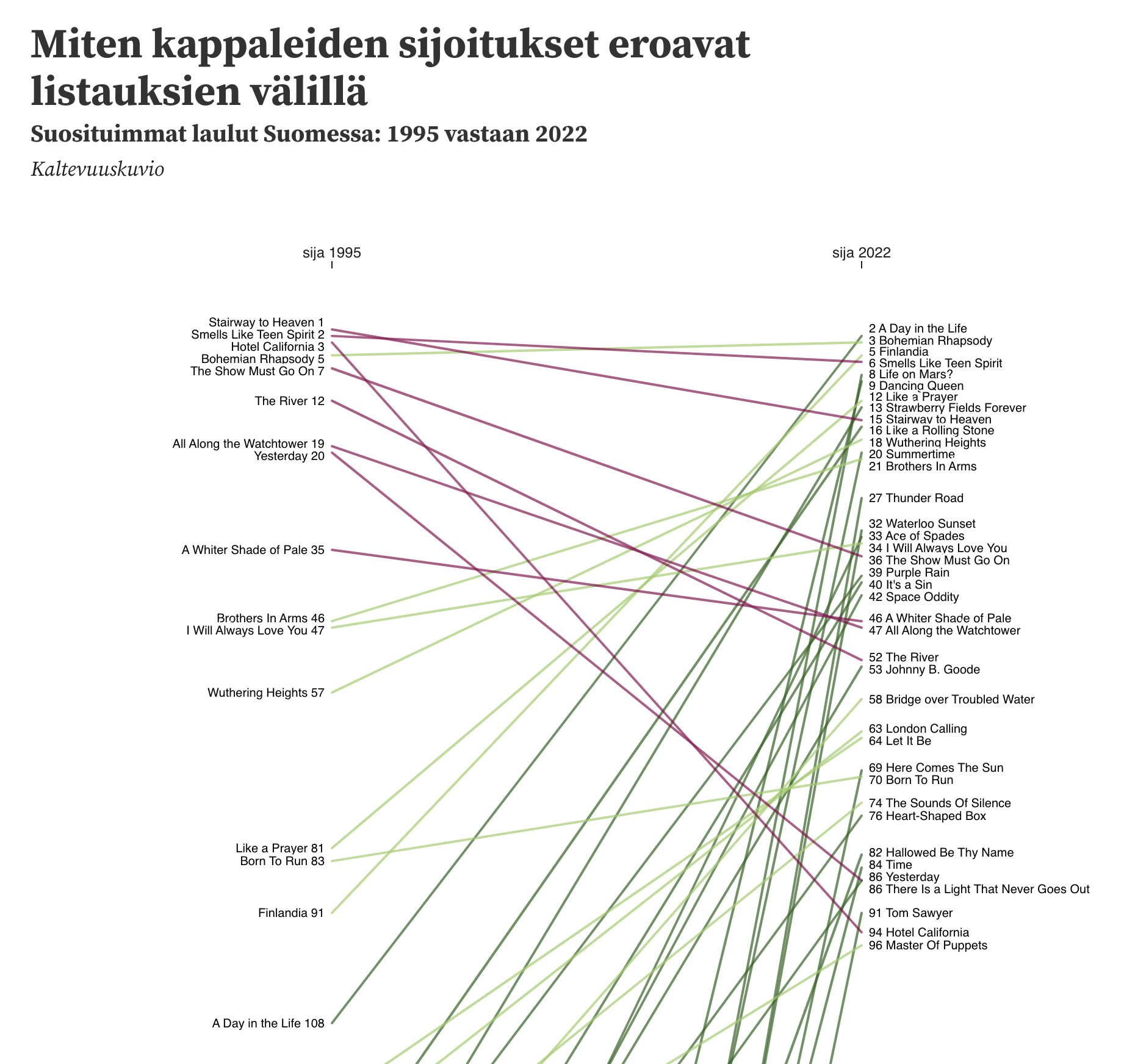
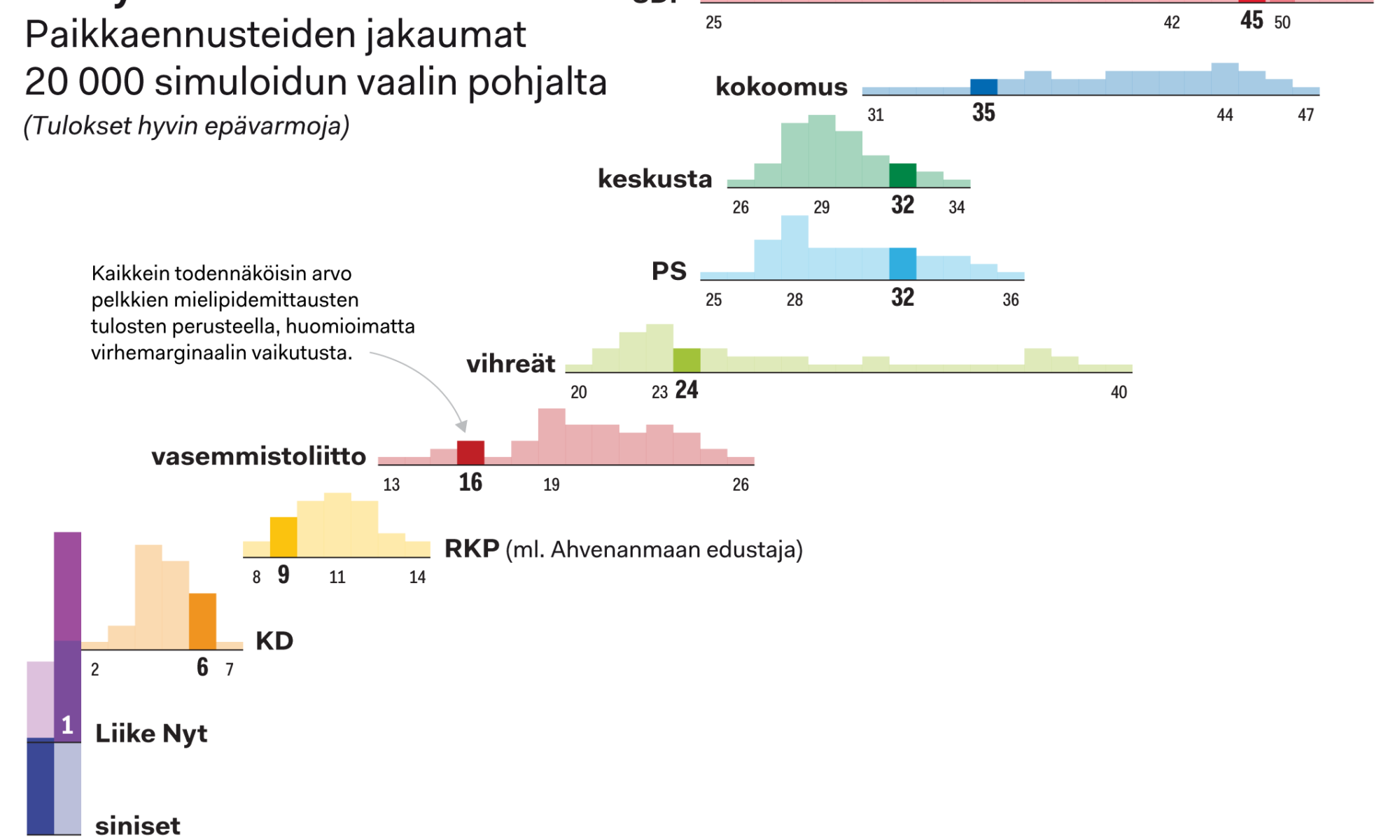
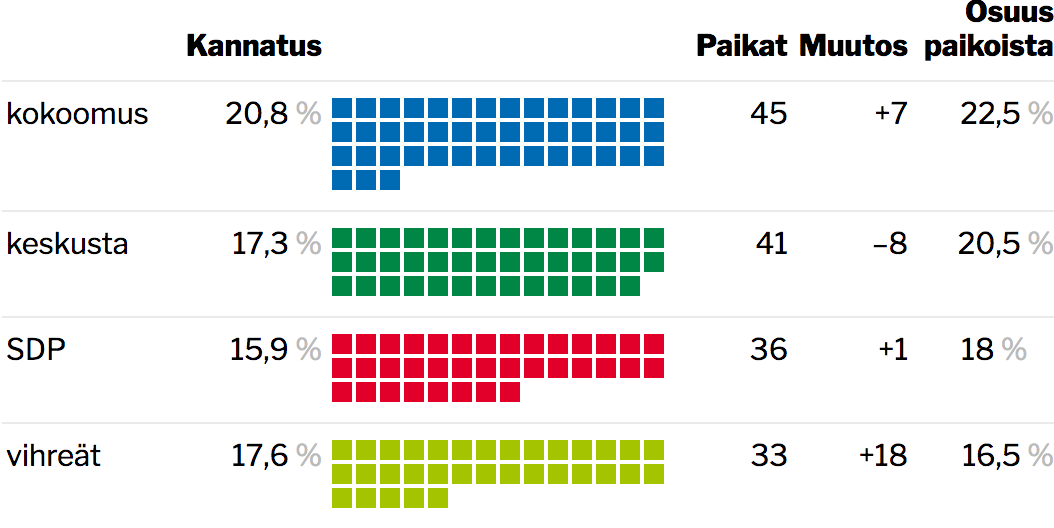
Arvokonservatiiviseksi vaihtoehtomediaksi itsensä määrittelevä Oikea Media julkaisi lauantaina Marko Hamilon kirjoittaman puolueiden kannatusta ja vieraskielisten osuutta Helsingin eri alueilla vertailevan datajournalismijutun otsikolla ”Maahanmuuton kannattajat asuvat kaukana monikulttuurisesta arjesta”.
Analyysin keskeinen sisältö tiivistetään Hamilon jutussa näin:
– – Sdp ja Perussuomalaiset saavat paljon ääniä monikulttuurisilta alueilta, sen sijaan Kokoomuksen ja Vihreiden kannatus on heikompaa siellä missä monikulttuurisuus on voimakasta. Vasemmistoliiton kannatus ei riipu äänestysalueen monikulttuurisuuden asteesta.
On ilahduttavaa, että konservatiivitkin yrittävät vaihteeksi käydä yhteiskunnallista keskustelua asia-argumentein. Valitettavasti artikkeli perustuu virheellisesti käsiteltyyn dataan eikä edes tämä virheellinen aineisto lähemmin tarkasteltuna täysin tue Hamilon sanallisesti esittämää tulkintaa.
Käytetty aineisto soveltuu tarkoitukseen huonosti ja käytetty menetelmä on kuvattu puutteellisesti
Puolueiden kannatuksen ja ”monikulttuurisuuden”, joka Hamilon artikkelissa määritellään vieraiden kielten puhujien osuudeksi, vertailu on lähtökohtaisesti hankalaa, sillä näistä teemoista saatavilla olevat tilastot käyttävät erilaista aluejakoa. Äänestysalueita ei käytetä väestötilastojen aluejakona, joten vieraiden kielten puhujien osuus on saatavilla vain niiden kanssa yhteensopimattomalla aluejaolla, esimerkiksi kaupunginosittain (Helsingin seudun aluesarjat -sivustolta) tai postinumeroalueittain (Tilastokeskuksen PAAVO-tietokannasta). Hamilo ilmoittaa käyttäneensä lähteenä aluesarjojen aiheistoa.
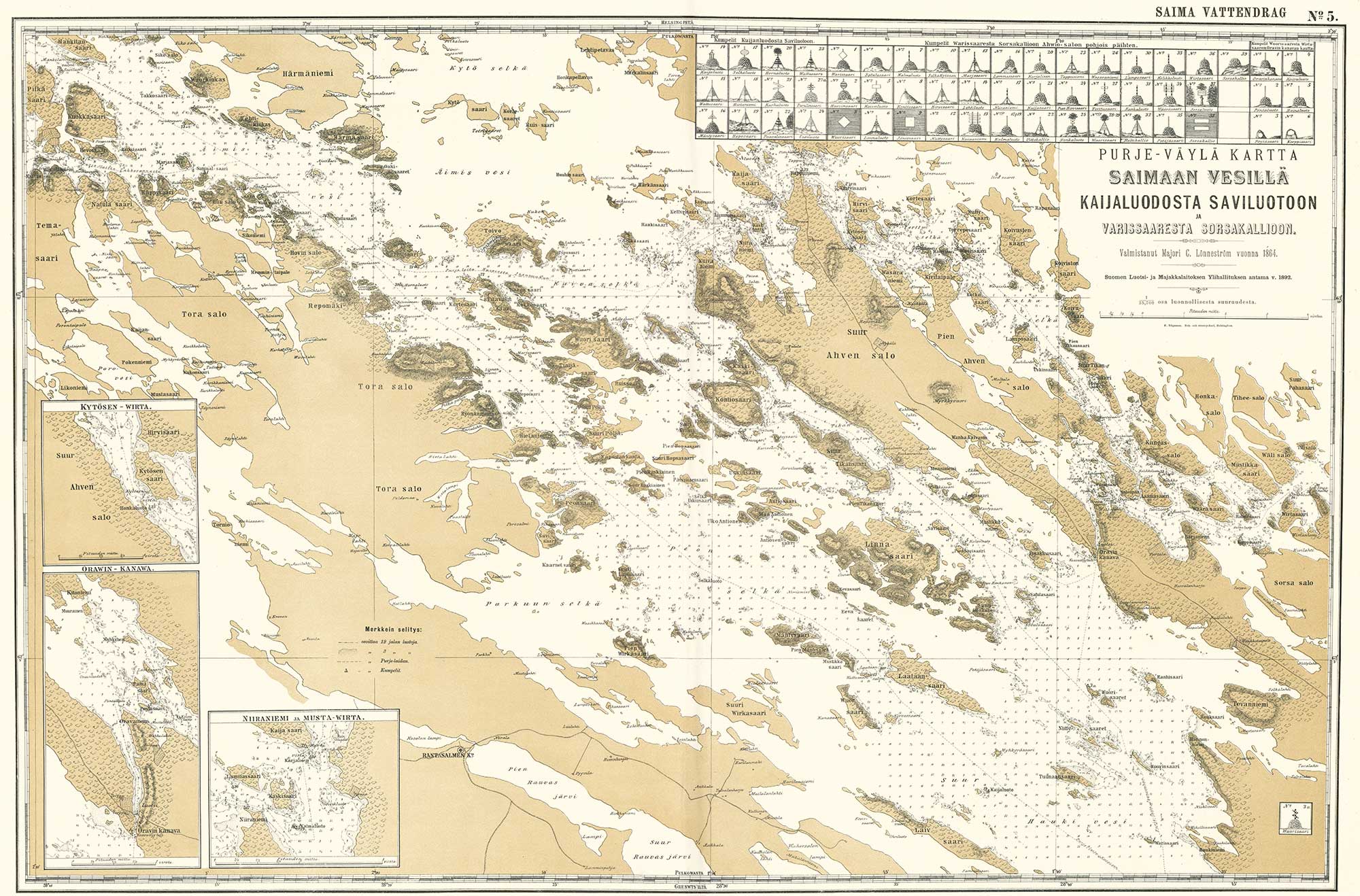
Alla oleva Helsingin kartta kuvaa sitä, miksi tämä on ongelma. Äänestysalueiden rajat eivät vastaa yksi yhteen kaupunginosien (tai postinumeroalueiden) rajoja. Kartassa mustalla näkyvät ne rajat, jotka ovat sekä kaupunginosien että äänestysalueiden rajoja, vihreällä vuoden 2012 kuntavaalien äänestysalueiden rajat ja oranssilla kaupunginosien rajat. Lisäksi vihreänharmaalla on merkitty ne äänestysalueiden rajat, jotka muuttuivat vuonna 2013.

(Kuva aukeaa klikkaamalla suuremmaksi.)
Sellaisissa tapauksissa, joissa kaikki kaupunginosaan kuuluvat äänestysalueet mahtuvat kokonaan sen rajojen sisäpuolelle ongelmaa ei synny, koska tällöin tulokset voidaan laskea yhteen ja muodostaa näin kaupunginosakohtaiset luvut. Ongelmia tuottavat sellaiset äänestysalueet, jotka ulottuvat kahden tai useamman kaupunginosan puolelle.
Yllä olevalla kartalla oranssina näkyvät kaupunginosien rajat ovat sellaisia kohtia, joissa äänestysalue ulottuu useamman kaupunginosan alueelle. Esimerkiksi äänestysalue 003A Kaartinkaupunki pitää sisällään Kaartinkaupungin kaupunginosan lisäksi myös Kaivopuiston sekä ison siivun Ullanlinnasta.
Hamilo ei selitä miten hän on ratkaissut aluejakojen yhteensovittamiseen liittyvät ongelmat. Asian selvittämistä hankaloittaa, että hän käyttää kaupunginosista pääosin muita kuin niiden virallisia nimiä. Joissain kohdin tämä on sisällöllisesti perusteltua: harva esimerkiksi tietää, että Itäkeskus ja Myllypuro kuuluvat molemmat virallisesti Vartiokylä-nimiseen kaupunginosaan (numero 45), joten nimitys Itäkeskus–Myllypuro on virallista nimeä havainnollisempi. Monet Hamilon valitsemat nimitykset ovat kuitenkin harhaanjohtavia: hän kutsuu esimerkiksi Länsisataman kaupunginosaa (20) Ruoholahdeksi, vaikka kaupunginosaan kuuluvat Ruoholahden lisäksi myös Jätkäsaari, Lapinlahti ja Hernesaari.
Hamilo vaikuttaa myös jättäneen viisi kaupunginosaa kokonaan pois analyysistään perustelematta ratkaisua mitenkään. Puuttuvat kaupunginosat ovat Kaivopuisto (09), Laakso (18), Vanhakaupunki (27), Viikki (36) ja Vartiosaari (48). Varsinkin n. 15 000 asukkaan Viikin jättäminen pois on erikoinen veto, joka kaipaisi jonkin perustelun tuekseen. Uskoisin tämän liittyvän jollain tavalla äänestysalueiden ja kaupunginosien yhteensovitusongelmaan, mutta kun metodologiaa ei ole tekstissä avattu, asia jää mysteeriksi.
Olen koonnut alla olevaan taulukkoon käsitykseni siitä, mitä virallisen aluejaon kaupunginosaa mikin Hamilon käyttämä nimitys tarkoittaa:
| Hamilon käyttämä kaupunginosan nimi |
kaupunginosan virallinen nimi ja numero |
asukasluku 1.1.2016 |
| Alppila |
12 Alppiharju |
11 937 |
| Etu-Töölö |
13 Etu-Töölö |
14 559 |
| Haaga |
29 Haaga |
26 771 |
| Hermanni |
21 Hermanni |
6 325 |
| Herttoniemi-Roihuvuori |
43 Herttoniemi |
26 216 |
| Itäkeskus-Myllypuro |
45 Vartiokylä |
33 956 |
| Jakomäki |
41 Suurmetsä |
16 209 |
| Kaartinkaupunki |
03 Kaartinkaupunki |
1 050 |
| Kallio |
11 Kallio |
19 434 |
| Kamppi-Hietalahti |
04 Kamppi |
11 709 |
| Kannelmäki-Malminkartano |
33 Kaarela |
27 357 |
| Käpylä |
25 Käpylä |
8 114 |
| Katajanokka |
08 Katajanokka |
4 470 |
| Kluuvi |
02 Kluuvi |
636 |
| Konala |
32 Konala |
6 197 |
| Kontula-Mellunmäki |
47 Mellunkylä |
37 600 |
| Koskela |
26 Koskela |
3 336 |
| Kruununhaka |
01 Kruununhaka |
7 376 |
| Kulosaari |
42 Kulosaari |
3 806 |
| Kumpula |
24 Kumpula |
3 838 |
| Laajasalo |
49 Laajasalo |
16 630 |
| Lauttasaari |
31 Lauttasaari |
22 617 |
| Malmi |
38 Malmi |
24 664 |
| Maunula |
28 Oulunkylä |
23 333 |
| Meilahti |
15 Meilahti |
5 091 |
| Munkkiniemi |
30 Munkkiniemi |
17 629 |
| Pakila |
34 Pakila |
10 399 |
| Paloheinä |
35 Tuomarinkylä |
8 982 |
| Pasila |
17 Pasila |
9 219 |
| Pitäjänmäki |
46 Pitäjänmäki |
11 726 |
| Pukinmäki |
37 Pukinmäki |
8 383 |
| Punavuori-Eira |
05 Punavuori + 06 Eira |
10 163 |
| Ruoholahti |
20 Länsisatama |
10 350 |
| Ruskeasuo |
16 Ruskeasuo |
10 373 |
| Santahamina |
51 Santahamina |
423 |
| Sörnäinen |
10 Sörnäinen |
9 634 |
| Suomenlinna |
52 Suomenlinna |
790 |
| Taka-Töölö |
14 Taka-Töölö |
15 244 |
| Tammisalo |
44 Tammisalo |
2 247 |
| Tapanila |
39 Tapaninkylä |
14 159 |
| Tapulikaupunki |
40 Suutarila |
19 901 |
| Toukola |
23 Toukola |
8 777 |
| Ullanlinna |
07 Ullanlinna |
10 629 |
| Vallila |
22 Vallila |
9 326 |
| Vuosaari |
54 Vuosaari |
37 834 |
| Östersundom |
55 Östersundom +
58 Karhusaari +
59 Ultuna |
1 961 |
| puuttuvat kokonaan |
09 Kaivopuisto
18 Laakso
27 Vanhakaupunki
36 Viikki
48 Vartiosaari |
yht. 17 901 |
Taulukosta ilmenee eräs muukin käytetyn aluejaon ongelma. Äänestysalueet ovat asukasluvultaan likimain samankokoisia, useimmiten noin 2 000–4 000 henkeä, joten niiden suora vertailu on vielä kohtalaisen mielekästä ilman sen kummempia painokertoimia. Hamilon vertailemien kaupunginosien asukasluvut kuitenkin vaihtelevat 423 asukkaan Santahaminasta 37 800 asukkaan Vuosaareen. On kyseenalaista, millaisia johtopäätöksiä näin erilaisia alueita suoraan vertailemalla voi ylipäänsä tehdä.
Hamilo on päätynyt yhdistämään vuosien 2008, 2011, 2012 ja 2015 vaalien tulokset yhdeksi luvuksi. Niin puolueiden kannatus kuin vieraskielisten määräkin on vaihdellut eri alueilla tällä ajanjaksolla paljon, eikä Hamilo selitä, miten hän on ottanut vaihtelun huomioon. Runsas vieraskielisten määrä vuonna 2015 tuskin on voinut vaikuttaa takautuvasti puolueiden kannatukseen vuonna 2008. (Pieniä lisähankaluuksia saattaa joissain kohdin tuottaa myös, että äänestysalueiden rajoja on muutettu vuosina 2010 ja 2013.)
Minulle jää myös epäselväksi, miten Hamilon ilmoittama vieraskielisten osuus eri kaupunginosissa on laskettu. Se ei aluesarjojen luvuilla nopeasti testailtuna vaikuttaisi olevan ainakaan vaalivuosien painotettu tai painottamaton keskiarvo, minkään yksittäisen vaalivuoden luku eikä myöskään tuorein Aluesarjat-sivustolta löytyvä luku eli tilanne vuoden 2016 alussa.
Jos analyysin olisi tehnyt jokin luotettava, journalistin ohjeisiin sitoutunut media, tai vielä parempaa, yliopistossa tai vaikkapa sektoritutkimuslaitoksessa työskentelevä ammattitutkija, saattaisin ehkä olla valmis uskomaan, että kaikille yllä mainitsemilleni erikoisille ratkaisuille löytyy hyvä perustelu ja ongelmakohdat on pystytty tavalla tai toisella taklaamaan. Hamilon ja Oikean Median uskottavuus ei kuitenkaan ole sillä tasolla, että ilman yksityiskohtaisia perusteluja voisi noin vain olettaa tekijän tietävän mitä tekee – varsinkin kun aineiston lähempi tarkastelu tuntuu pikemminkin lisäävän kysymyksiä kuin vastaavan niihin.
Edes Hamilon käyttämä data ei tue hänen johtopäätöksiään
Kelpuuttakaamme kuitenkin keskustelun vuoksi Hamilon käyttämä data kaikkine epäselvyyksineenkin. Tukeeko käytetty aineisto kirjoittajan sanallista tulkintaa? Hamilo toteaa kuvioiden lukuohjeessa mm. näin:
Jos puolueen kannatus korreloi positiivisesti monikulttuurisuuden kanssa, on trendi nouseva oikealle mentäessä.
Hamilo on siis kiinnostunut siitä, miten puolueen kannataus korreloi ”monikulttuurisuuden” (eli vieraskielisten osuuden kanssa). Tässä kohdin on hyvä muistuttaa siitä, mitä korrelaatio oikeastaan tarkoittaa. Tiivis määritelmä löytyy esimerkiksi Tieto näkyväksi -kirjasta (s. 195):
Korrelaatio eli yhteisvaihtelu on suure, joka kuvaa kahden muuttujan keskinäistä riippuvuussuhdetta. Tiedämme esimerkiksi, että ihmisen tulotasolla ja eliniänodotteella on yhteys toisiinsa: suurituloiset elävät keskimäärin pienituloisia vanhemmiksi. Havainto pätee tilastollisella tasolla, vaikka yksilötasolla tästä esiintyykin runsaasti poikkeuksia.
Voimakas korrelaatio viittaa siihen, että muuttujien välillä on jonkinlainen syy-yhteys, mutta ei kerro sitä, kumpi muuttujista on syy ja kumpi seuraus tai löytyykö keskinäisen riippuvuuden takaa kenties jokin kolmas selittävä tekijä. Tämä ei käy ilmi pelkästään tilastollisesta analyysistä, vaan syy–seuraussuhteen selvittäminen vaatii syvällisempää tietoa aiheesta.
Korrelaation laskemiseen on useita matemaattisia menetelmiä, joista käytetyin on Pearsonin korrelaatiokerroin eli r. Se voi saada arvoja välillä –1 … 1. Korrelaatio on sitä voimakkaampi, mitä enemmän r:n arvo poikkeaa nollasta. Negatiiviset arvot kuvaavat käänteistä riippuvuussuhdetta, jossa toisen muuttujan arvo kasvaa toisen pienentyessä.
– –
Tilanteet, joissa r olisi tasan 0, 1 tai –1 ovat varsin harvinaisia. Useimmin korrelaatiokertoimen arvo asettuu jonnekin niiden välimaastoon. Mikä silloin on voimakas tai heikko korrelaatio? Ohessa suuntaa antava jaottelu:
r = 0–0,2 ei korrelaatiota
r = 0,2–0,4 heikko korrelaatio
r = 0,4–0,6 kohtalainen korrelaatio
r = 0,6–0,8 voimakas korrelaatio
r = 0,8–1 erittäin voimakas korrelaatio
Korrelaatio on siis matemaattinen suure, jonka suuruus voidaan visualisoinnista arvioida silmämääräisesti vain karkeasti, mutta jonka laskemiseen on olemassa vakiintunut ja helppo menetelmä.
Jostain syystä Hamilo ei ole laskenut puolueiden kannatuslukujen ja ”monikulttuurisuuden” asteen välisiä korrelaatiokertoimia, vaan nojaa pelkästään laatimiinsa visuaalisiin esityksiin, joita hän tulkitsee lukijalle sanallisesti.
Alla olevaa kuviota tulkitaan mm. näin: ”Vihreiden vankin kannatus löytyy kantasuomalaisten asuttamilta alueilta ja kannatus laskee monikulttuurin lisääntyessä.”

Seuraavaa grafiikkaa kuvaillaan vuorostaan näin: ”Vasemmistoliiton kannatus näyttää olevan tasaista kautta linjan, eikä siis riipu alueen monikulttuurisuusasteesta.”
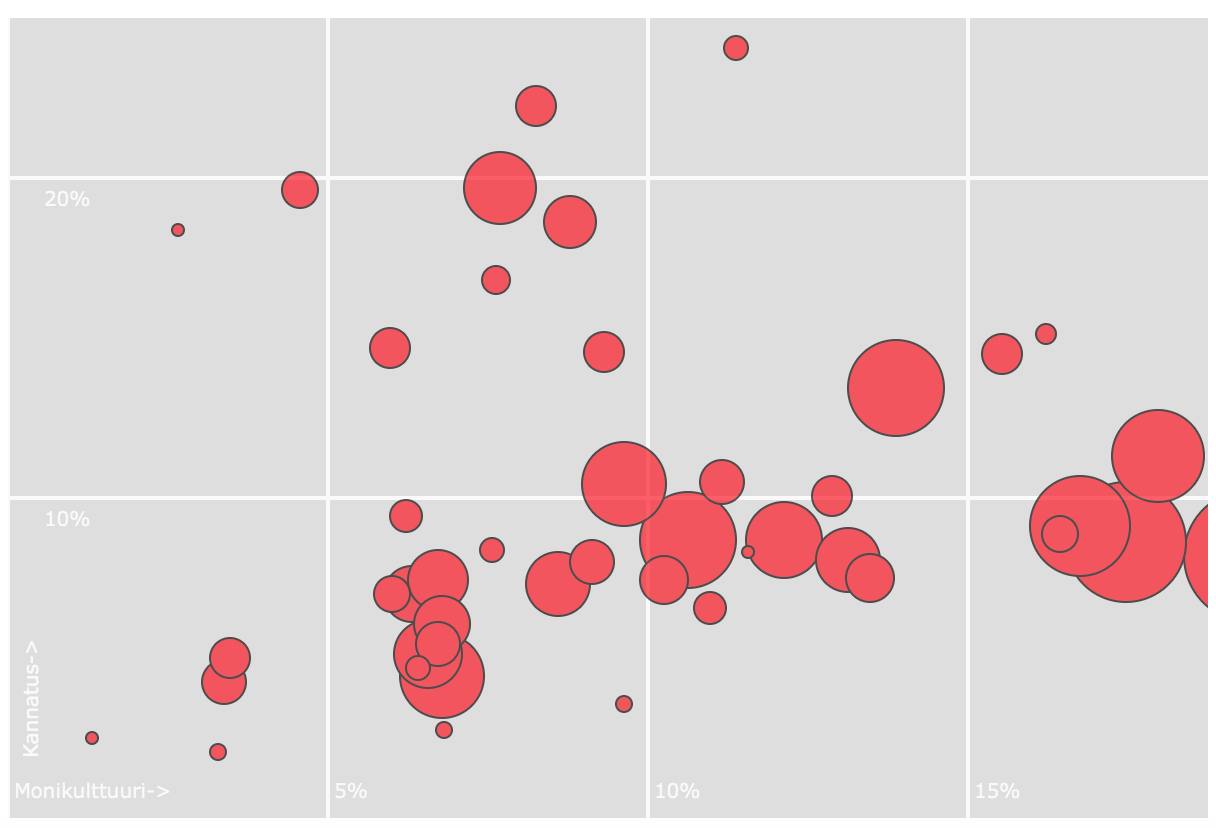
Minun täytyy sanoa, etten näe kuvioissa Hamilon kuvailemaa eroa. Minun silmiini kumpikaan niistä ei paljasta selkeää yhteyttä puolueen kannatuksen ja ”monikulttuurisuuden” välillä, vaan kaupunginosia kuvaavat pallot ovat kummassakin kuviossa melko lailla hajallaan ympäri koordinaatistoa.
Onneksi asiassa ei tarvitse luottaa pelkkään silmämääriseen arvioon, vaan voimme laskea puolueen kannatuksen ja vieraitten kielten puhujien osuuden korrelaation kullekin puolueelle:
| puolue |
korrelaatio |
| SDP |
0,72 |
| kokoomus |
−0,55 |
| perussuomalaiset |
0,51 |
| vihreät |
−0,18 |
| vasemmistoliitto |
0,15 |
SDP:n ja monikulttuurisuuden väillä näkyy Hamilon keräämän datan perusteella olevan voimakas (r = 0,72) positiivinen korrelaatio. Myös kokoomuksen ja perussuomalaisten kohdalla korrelaatio on kohtalainen, kuten Hamilo jutussaan kuvaileekin.
Mutta kas vain! Vihreiden ja vasemmistoliiton korrelaatiokertoimet ovat käytännössä samansuuruisia, vaikkakin toki vastakkaissuuntaisia. Toista näistä Hamilo kuvailee siis sanomalla, että ”kannatus laskee monikulttuurin lisääntyessä”, toista taas, ettei kannatus ”riipu alueen monikulttuurisuusasteesta”.
Alle 0,2:n korrelaatiota kuvaillaan yleensä sanoilla ”ei korrelaatiota”. Toisin sanoen, Hamilon väite siitä, että vihreiden kannatus olisi kääntäen verrannollinen ”monikulttuurisuuden” määrään ei kestä lähempää tarkastelua edes hänen omaa dataansa käyttäen. Hamilo on päättänyt analyysinsä tuloksen etukäteen ja näkee kuviossa mitä haluaa, vaikka yksinkertainen tilastollinen analyysi olisi paljastanut, ettei aineisto tue tehtyä johtopäätöstä. Tämä siis sen lisäksi, ettei käytetty aineisto sovi tällaisen analyysin tekemiseen ja sitä on käsitelty virheellisesti ja läpinäkymättömästi.
Näiden puutteiden lisäksi voisin listata vielä lisääkin. Esimerkiksi: Miksi tarkastelu on rajattu vain Helsinkiin? Eikö vähintään muut pk-seudun kunnat ja kenties muutkin suuret kaupunkiseudut olisi syytä ottaa mukaan isomman otoksen ja siten robustimman analyysin aikaansaamiseksi?
Entäpä miksi jutussa ei ole lainkaan käsitelty vaihtoehtoisia selityksiä havaituille puoluekannatuksen alueellisille eroille? Uskaltaisin veikata, että sekä asuinpaikka että puoluekannatus korreloivat voimakkaammin tulotason kanssa kuin puolekannatus alueen vieraskielisten määrän kanssa. Varsinkin kun Hamilon implikoitu väite – että maahanmuuttajien lähellä asuminen lisäisi maahanmuuttovastaisia asenteita ja siten perussuomalaisten suosiota – on ristiriidassa olemassaolevan tutkimustiedon kanssa, vaadittaisiin vähän kattavampaa vaihtoehtoisten selitysmallien poissulkemista, jotta analyysi olisi uskottava.
Datajournalismin tarkoitus ei ole väännellä ja käännellä aineistoa halutun lopputuloksen saamiseksi. Oikean Median ja Hamilon kannattanee vastaisuudessa jättää tämä laji osaavampien heiniksi.
Olen kerännyt kaikki käytetyt datat yhteen CSV-muotoiseen taulukkoon, jonka halukkaat voivat ladata omien analyysien tekemistä varten.