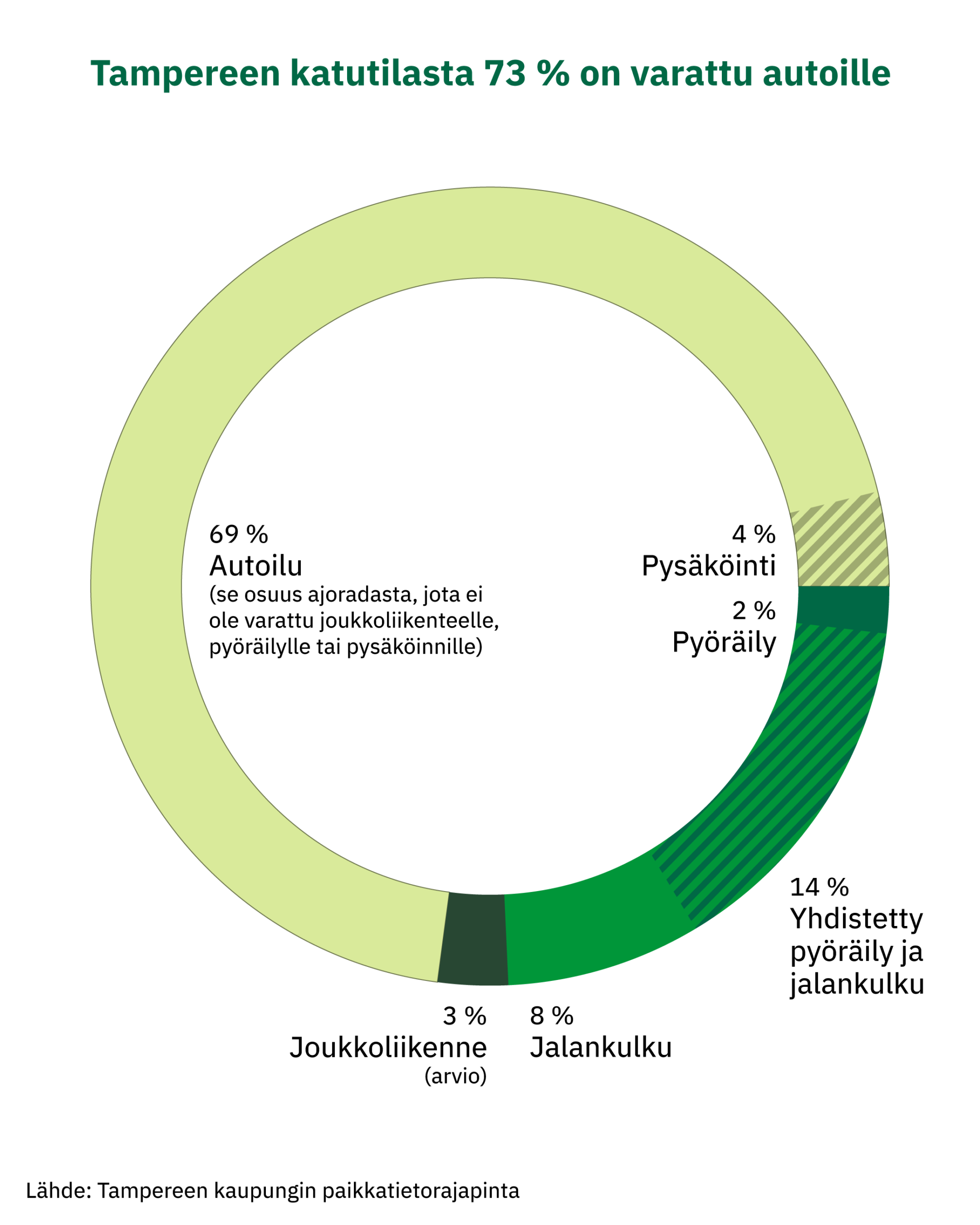
Tampereen katutilasta arviolta 73 % on varattu käytännössä autoille. Kävelylle ja pyöräilylle on osoitettu katutilasta selvästi pienempi siivu, 24 %. Joukkoliikenteelle jää vaivaiset 3 % ratikan liikennöinnin aloitettuakin. Helsinkiin verrattuna yhdistetyn pyöräilyn ja jalankulun osuus on selvästi isompi.
Tampereen keskustassa kulkumuotojen välset suhteet jakautuvat hieman tasaisemmin. Autoilulle on varattu 58 %, kun kävelylle ja pyöräilylle jää 38 %. Joukkoliikenteen osuus on 4 %.
Myös Tampereella autoilu vie hyvin suuren osan katutilasta, jos vertailee autolla tehtyjen matkojen määrään. Koska autolla tehdään pidempiä matkoja kuin jalan tai pyörällä, ero henkilökilometreissä on pienempi.
Kulkumuotojakauman tiedot perustuu Henkilöliikennetutkimukseen 2021 ja sisältävät siten tamperelaisten tekemät matkat myös kaupungin ulkopuolella.
Kuten Helsinginkin tapauksessa, nämä luvut ovat vain arvioita, sillä suoraa valmista dataa ei ole saatavilla. Niistä saa kuitenkin hyvän suuntaa antavan käsityksen siitä, kuinka eri kulkumuotoja on priorisoitu kaupunkitilassa. Ajoratoja käyttää toki myös julkinen liikenne sekä pienemmässä määrin polkupyörät.
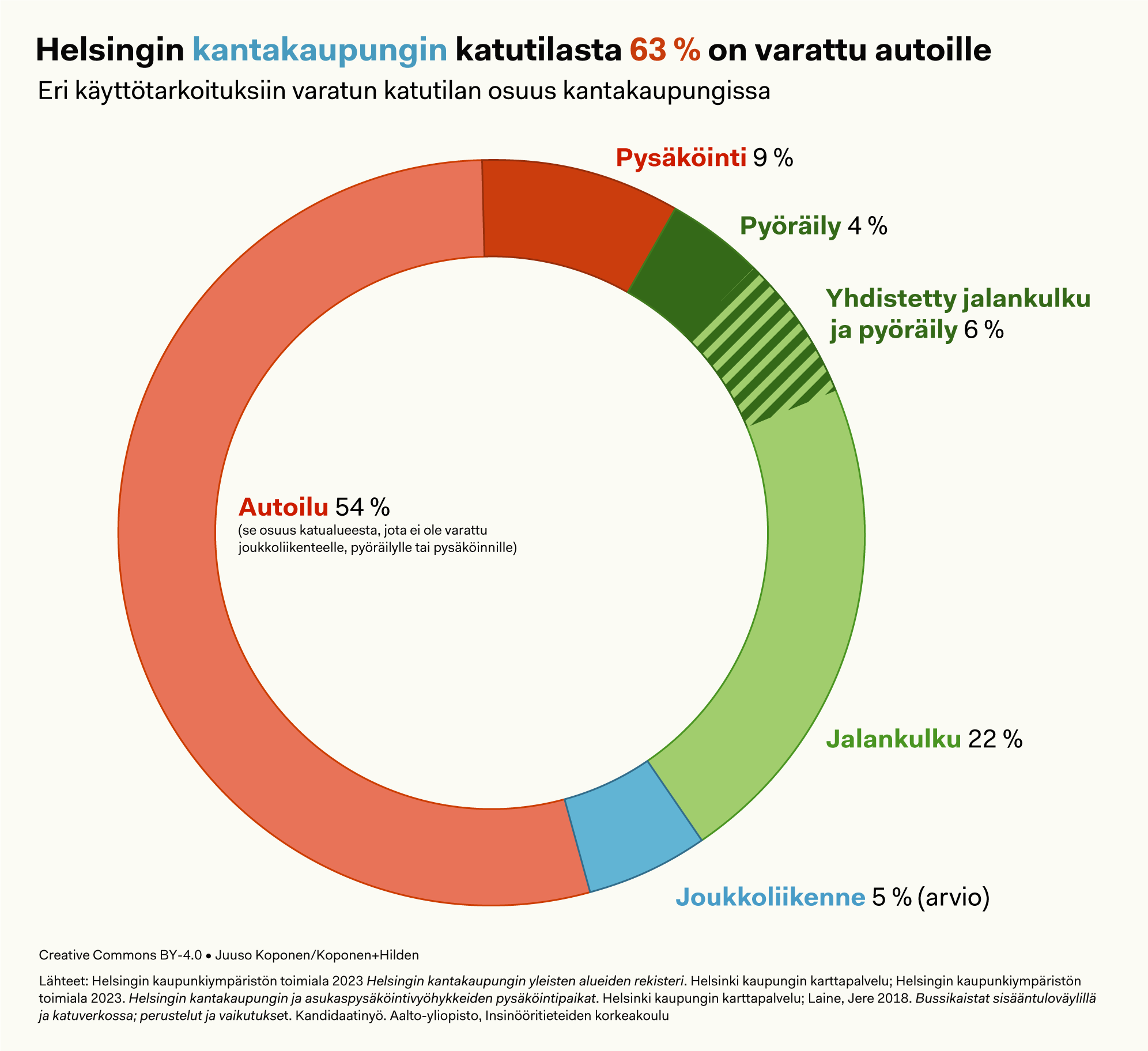
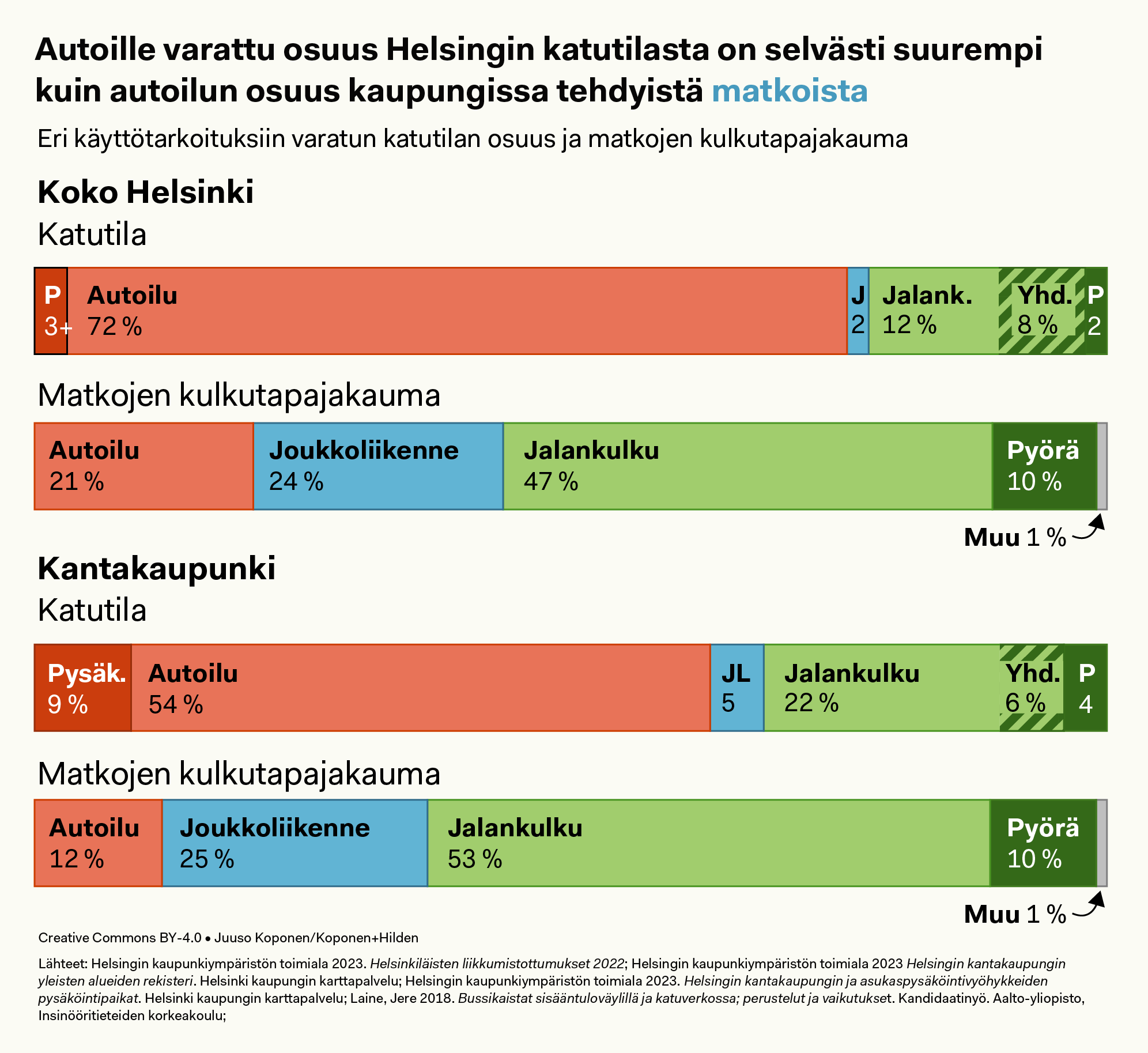
Koko Helsingin katutilasta (ylempi grafiikka) noin 75 % ja kantakaupungin katutilasta noin 63 % on varattu autoille (alempi grafiikka). Luvut eivät ole täysin tarkkoja, koska joukkoliikenteen käytössä olevan osuuden suuruudesta ei ole käytettävissä tietoja. Autoilun osuus on siis se osa katualueesta (ei ajoradasta), joka ei ole varattu muuhun käyttöön. Katualueeseen kuuluu ajoradan lisäksi esim. kaistojen välinen alue moottoriliikenneteillä.
Ylipäänsä katutilan määrittely rekisteriaineistojen perusteella on yllättävän vaikeaa! Olemme käyttäneet seuraavaa rajausta: mukana ovat kaikki katualueeksi yleisten alueiden rekisterissä määritellyt alueet sekä kevyen liikenteen väylistä ne, jotka eivät kulje puistoissa. Joukkoliikenteen käytössä olevaksi on arvioitu HKL:n, HSL:n tai Liikenneviraston huoltovastuulla olevat katuosat, joka sisältää mm. muusta liikenteestä erotellut raitiovaunukiskot ja raitiovaunupysäkit. Tämän lisäksi on arvioitu bussikaistojen ja -pysäkkien viemä tila.
Bussikaistojen kokonaismääräksi Helsingissä on Jere Laineen kandidaatintyöstä saatu 44 km, mutta ei ole tietoa, miten tämä jakautuu kantakaupungin ja esikaupunkien välillä. Olemme olettaneet, että bussikaistoista 1/3 on kantakaupungissa ja että niiden leveys on keskimäärin 3,5 metriä. Bussipysäkkien kokonaismäärä ja jakautuminen on tiedossa, mutta niiden viemä tarkka pinta-ala ei tiedetä. Tässä on arvioitu, että kukin bussipysäkki vie keskimäärin 50 m² ajoradalta ja 10 m² jalkakäytävältä. Pysäköintipaikkojen viemän tilan osuus on tässä arviossa koko kaupungin osalta liian pieni, sillä käytettävissä olevassa aineistossa ei ole mukana asukaspysäköintivyöhykkeen ulkopuolella sijaitsevia kadunvarsipaikkoja.
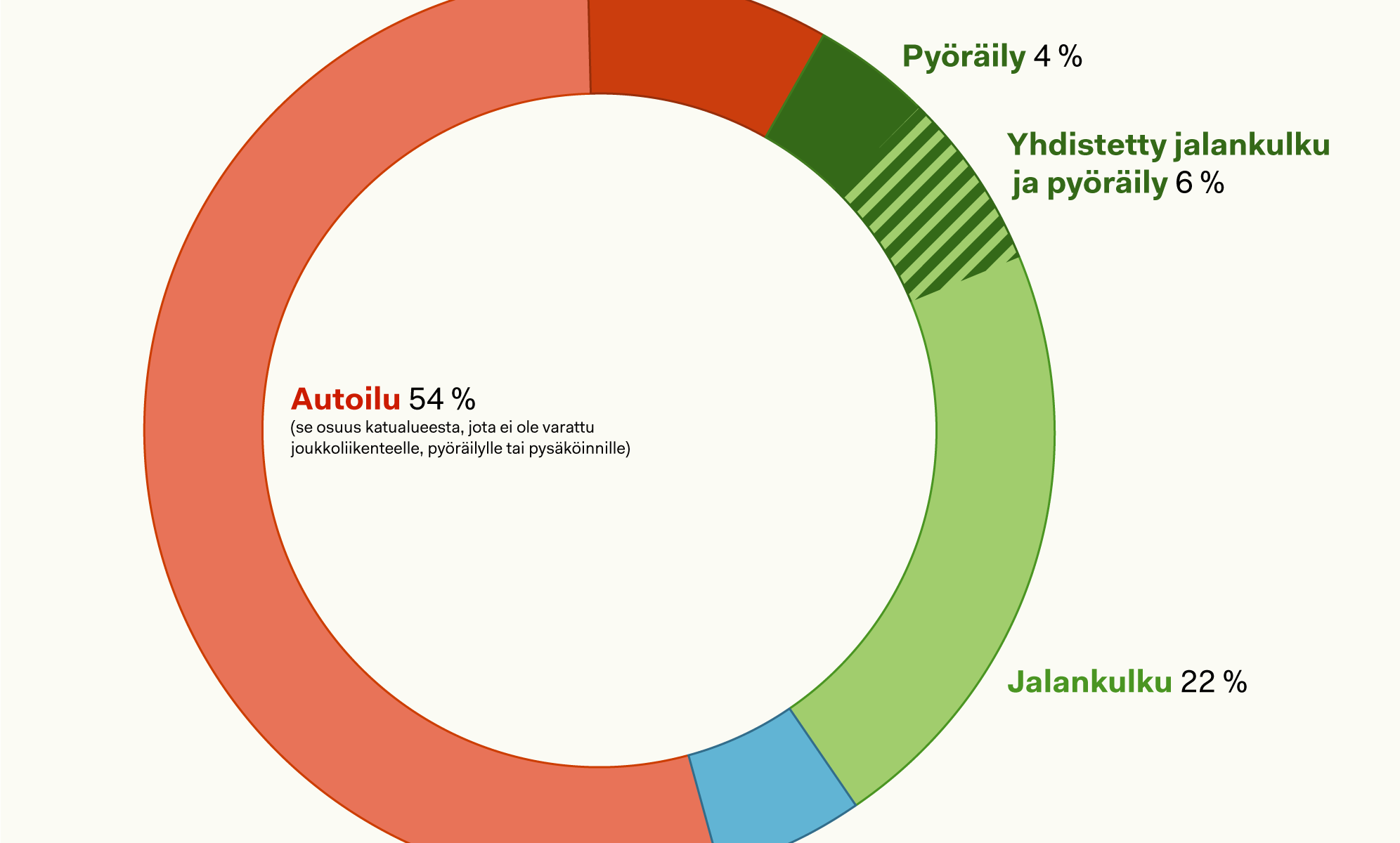
Autoilulle varattu osuus katutilasta on sekä kantakaupungissa että koko Helsingissä selvästi suurempi kuin autoilun osuus kaupungissa tehdyistä matkoista, kuten alla olevasta grafiikasta ilmenee.
Suhteutettuna matkasuoritteeseen eli kullakin kulkuneuvolla tehtyjen matkojen pituuteen jakauma vaikuttaa tasaisemmalta. On kuitenkin huomioitava, että tässä käytetyssä aineistossa (Henkilöliikennetutkimus 2021) matkat on eroteltu vain vastaajan kotipaikan mukaan.
Toisin sanoen mukana ovat kaikki helsinkiläisten tai kantakaupungissa asuvien tekemät matkat, tapahtuivat ne missä päin Suomea hyvänsä. Mukana ovat myös pitkät lomamatkat, mikä näkyy esim. kategorian ”muu” (joka sisältää moottoripyörät ja matkailuautot) suuruutena. Kuten Henkilöliikennetutkimuksesta selviää, suomalaiset tekevätkin varsin paljon pitkiä matkoja autolla. Koko maassa 20–150 km mittaisilla matkoilla henkilöauto on täysin dominova kulkutapa, osuus on 93 % – 94 %. Aineistoa matkasuoritteen jakautumisesta kulkutavoittain Helsingin sisällä ei valitettavasti ole saatavilla.
Post scriptum
Muutama sananen siitä, miksi tämä laskelma antaa varsin erilaisen lopputuloksen kuin aiemmin tekemässämme grafiikassa katutilan jakautumisesta Helsingin kantakaupungissa. Uuden laskelman tekemiseen ryhdyttiin, jotta saataisiin lukuja, jotka ovat vertailukelpoisia muihin Suomen kaupunkeihin. Sitä tehdessä pyrittiin huomioimaan Twitterissä laskelmaa kohtaan esitetty kritiikki ja huomioimaan aiempaa paremmin joukkoliikenteen osuus.
Laskelma tehtiin alusta asti uusiksi ja siinä hyödynnettiin dataa aiempaa hienojakoisemmin. Alueiden pinta-alat laskettiin yhteen jo paikkatieto-ohjelmistossa kuin aikaisemmassa versiossa lopullinen yhteenlasku tapahtui Python-koodin avulla. Alkuperäinen laskelma ei ole säilynyt aivan kokonaisuudessaan, mutta säilyneiden tietojen perusteella siinä vaikuttaa olevan kaksi keskeistä virhettä.
Tekemämme Python-koodi laski kevyen liikenteen väylistä virheellisesti yhteen vain puhtaanapitovyöhyke 1:een (ydinkeskusta ja turistikohteet) kuuluvat alueet. Tämä alue on pienempi kuin koko kantakaupunki, joten kevyen liikenteen väylien pinta-ala jää näin liian pieneksi
Kadunvarsipysäköinnin vaatima tila perustuu ilmeisesti arvioon, joka on selvästi liian suuri. (Tämä laskelma ei valitettavasti ole säilynyt.) Tämä virhe ei vaikuta autoille varatun tilan suuruuteen, vaan ainoastaan siihen miten se jakautuu ajoradan ja pysäköinnin kesken.
Laskelmien tuloksissa on muitakin pieniä eroja, jotka selittyvät lähinnä datan hienojakoisempien tietojen tarkemmalla hyödyntämisellä ja todellisilla muutoksilla katutilassa (esim. uudet pyöräväylät), mutta nämä kaksi virhettä selittävät suurimman osan eroista.
Kirjaa varten tehtiin myös kartta kaikista säilyneistä Engelin Helsinkiin suunnittelemista rakennuksista. Kartta piirrettiin Antti Aaltosen tekemän kartan pohjalta joka löytyi Rakennustaiteen museolta, ja Engel-asiantuntija Jarkko Sinisalo konsultoi yksityiskohdissa.
Kiinnostava asia tässä kartassa on, että siitä puutuu kaksi tunnettua rakennusta, joita laajasti pidetään Engelin piirtäminä: Kaivohuone ja Ravintola Kaisaniemi. Muun muassa Kaupunginmuseo sanoo Ravintola Kaisaniemen Engelin piirtämäksi.
Engelin rakennukset nykypäivän Helsingissä. Kartta-aukeama kirjasta, vasen puoli.
Sinisalon laatima kartan kuvateksti: C. L. Engel suunnitteli Helsingin rakennuksia uudelleenrakennustoimikunnan arkkitehtina (1816–1824), yleisten rakennusten intendenttinä eli Intendentinkonttorin päällikkönä (1824–1840), yliopiston arkkitehtina sekä yksityishenkilöiden toimeksiannosta. Intendentinkonttorin suunnitelmista on yleensä vaikea ratkaista, milloin suunnitelma on Engelin omaa työtä, milloin vain laadittu hänen johdollaan.
Kartalla on eritelty Engelin itsensä piirtämät rakennukset (tiilenvärinen) sekä Intendenttikonttorin piirtämät rakennukset (oranssi).Kartta-aukeama kirjasta, oikea puoli.
Minulla ei ole tallessa täydellistä dokumentointia keskusteluista, mutta muistan, että Ravintola Kaisaniemen poisjättö oli itsestäänselvyys. Engel oli puistoon suunnitellut jonkun aiemman rakennuksen, mutta nykyinen ja myös kunnostushankkeen vuoksi ajankohtainen talo ei ole hänen käsialaansa.
Kaivohuone oli taas kiistanalaisempi tapaus. Mitä ilmeisemmin alkuperäiset piirustukset olivat jo kauan sitten hävinneet ja sitä on katsottu Engelin piirtämäksi lähinnä tyylihistoriallisin perustein*. Sinisalon mielipide oli, että sitä ei tämän pohjalta voi merkata Engelin piirtämäksi. Näin sekin jäi kartalta pois.
Mutta näin ollen, uskoakseni tämä on tarkin tähän mennessä julkaistu kartta Engelin rakennuksista Helsingissä.
Kartalla mainitut rakennukset listattuna
Nikolainkirkko, nyk. Helsingin tuomiokirkko — Nikolaikyrkan, nuv. Helsingfors domkyrka
Senaatintalo, nyk. valtioneuvoston linna – Senaten, nuv. Statsrådsborgen
Kenraalikuvernöörin talo (Bockin talo) – Generalguvernörens hus (Bockska huset)
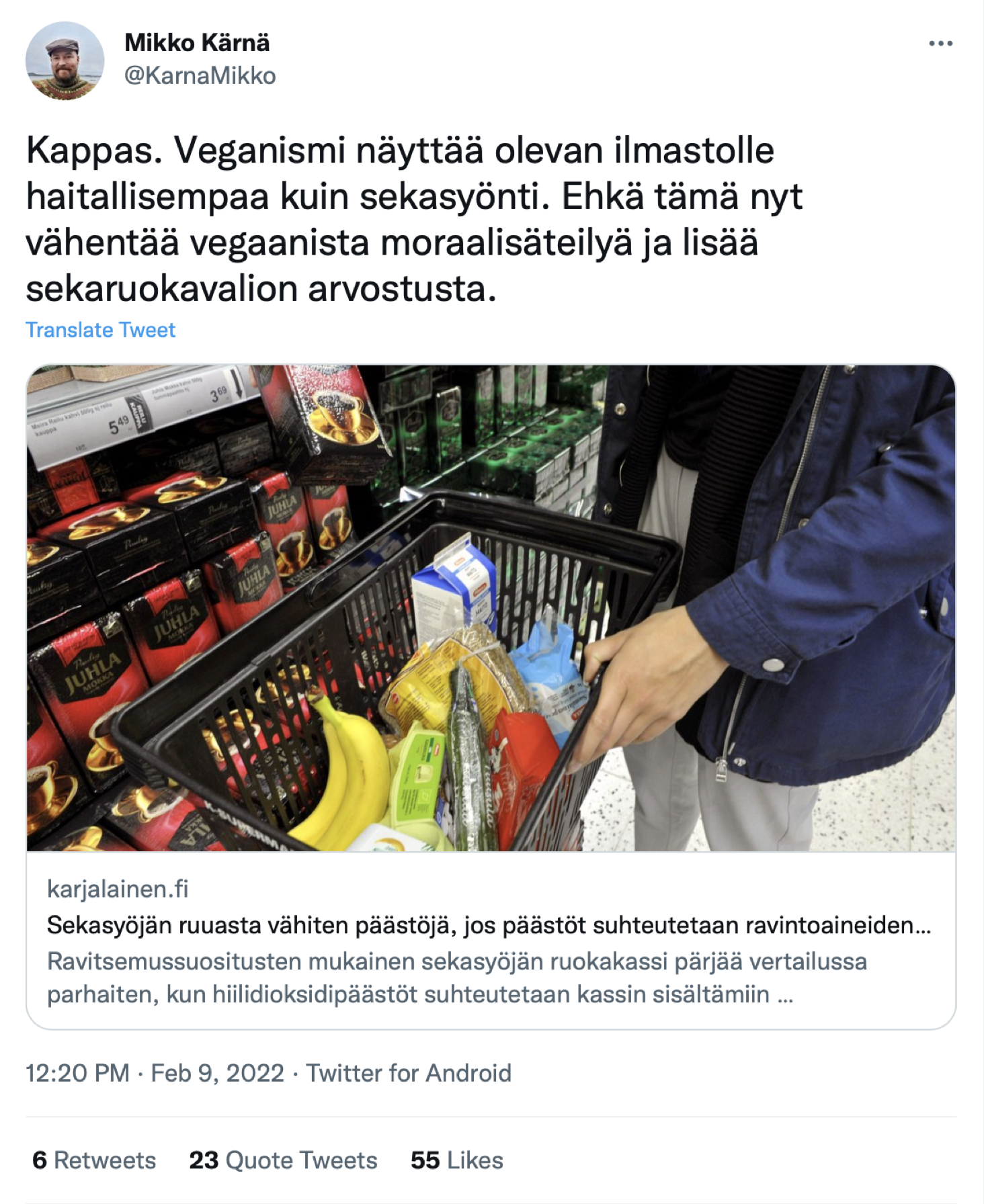
Opetan XAMKin data-analytiikan koulutusohjelmassa kurssia ”Ajankohtaiset kysymykset ja datavaikuttaminen”, joka käsittelee mm. sitä, miten valtiot, yritykset ja järjestöt käyttävät dataa mielipiteenmuokkauksen ja lobbauksen välineenä. MTK:n viime viikolla julkistama ruokakassivertailu on tyylipuhdas esimerkki tällaisesta datavaikuttamisesta ja toimi kurssillamme erinomaisena case-esimerkkinä. Samalla se osoittaa kuitenkin myös kiinnostavasti, että vaikuttaminen ei aina mene putkeen.
MTK julkisti keskiviikkona 9.2. selvityksen, jossa vertailtiin neljän S-ryhmän ostosdataan perustuvan ruokakassin sekä viidennen, suomalaisiin ravitsemussuosituksiin perustuvan kassin päästöjä niiden sisältämiin ravintoarvoihin suhteutettuna. Viestinnälliseksi kärjeksi oli nostettu, että ravitsemussuositusten mukainen sekasyöjän ruokakassi aiheutti ravintosisältöönsä verrattuna täpärästi pienemmät päästöt kuin kasvispainotteinen, alle 34-vuotiaiden kaupunkilaisten ostosten perusteella muodostettu kassi.
Tähän media tarttui hanakasti. STT:n juttu selvityksestä oli otsikoitu ”Selvitys: Sekasyöjän ruuasta vähiten päästöjä – jos päästöt suhteutetaan ravintoaineiden saantiin”. Jotkut lehdet, esimerkiksi Karjalainen, lyhensivät sen muotoon ”Sekasyöjän ruuasta aiheutuu vähiten päästöjä”.
Selvityksen alkuperäinen, varsin maltillinen löydös paisui matkalla siis melkoisiin mittoihin. MTV3:n uutiset sai sen pyöräytettyä peräti muotoon ”Sekasyönti onkin ilmastoteko”.
Otsikoinnilla on suuri merkitys, sillä moni meistä ei vaivaudu lukemaan otsikkoa pitemmälle varsinkaan silloin, kun se tukee omia ennakokäsityksiä. Pelkän otsikon perusteella innostuivat twiittaamaan niin tavalliset pulliaiset kuin kansanedustajatkin.
Jos selvityksen materiaalit lukee huolella, selviää kuitenkin, että yksikään vertailussa mukana olleista ruokakasseista ei ollut vegaaninen vaan myös 34-vuotiaiden kaupunkilaisten ostoksiin perustuvassa kassissa oli mukana kalaa ja kananmunia. Tämä huomattiin somessa nopeasti. Media joutuikin pian korjailemaan uutisointia. Varsinaisia oikaisuja ei ole omiin silmiini sattunut, mutta ainakin MTV3 ”tarkensi” uutistaan varsin näkyvästi. STT laati uuden, alkuperäistä selvästi laajemman jatkojutun, jonka monet lehdet julkaisivat. Tämä saattoi olla viestinnällisesti oma maali MTK:lle, sillä alkuperäisen uutisen väitteet kiistävä jatkojuttu tavoitti luultavasti alkuperäistä enemmän lukijoita. Myös somessa huomio oli voittopuolisesti negatiivista.
Korjatustakin uutisoinnista voi kuitenkin jäädä käsitys, että lihaton ja maidoton ruokakassi ei olisi ilmastovaikutuksiltaan lihaa ja maitotuotteita sisältävää, ravitsemussuositusten mukaan koottua kassia parempi. Tämä ei pidä paikkaansa. MTK:n käyttämä tapa laskea ruuan ravintoainetiheyttä on tarkoitushakuinen ja liioittelee eläinperäisten tuotteiden ravintoarvoja. Kuvaan seuraavassa, miten se toimii ja kuinka se tuottaa sopivilla valinnoilla absurdeja tuloksia.
Laskelman on MTK:lle tuottanut Envitecpolis-konsulttiyhtiön asiantuntija Senja Arffman. Se perustuu ilmeisesti alkujaan Arlan tilaamaan työhön, josta muokattiin MTK:n tarpeisiin sopiva alkujaan vuonna 2020, jolloin vertailtiin broileri- ja sushiaterian päästöjä. Jo tuolloin laskelma oli laadittu ilmeisen tarkoitushakuisesti ja se saikin osakseen laajaa kritiikkiä, jota on hyvin koottu yhteen Ruokamysteerit-blogissa. Kriittisiä kommentteja esittivät tuolloin mm. ravitsemusasiantuntija Mikael Fogelholm ja ilmastoasiantuntija Oras Tynkkynen.
Vuoden 2020 indeksi laskettiin vertaamalla annosten sisältämien vitamiinien ja kivennäisaineiden määrää per 100 g ravitsesuosituksen mukaiseen päivän saantisuositukseen. Energiaravintoaineiden osalta vertailukohtana oli se, mikä osuus ravinnosta saatavasta energiasta (E%) tulisi vähintään saada kustakin ravintoaineesta per 1 000 kcal. Kummassakin tapauksessa pudotettiin pois sellaiset ravintoaineet, joiden saanti oli alle 15 % suosituksesta. Raja on valittu mielivaltaisesti ja vaikuttaa tarkoitushakuiselta, sillä se suosii eläinperäisiä tuotteita kasviraaka-aineiden kustannuksella. Lisäksi laskutapaa kritisoitiin siitä, että energiaravintoaineista mukana oli vain proteiini ja välttämättömät rasvahapot. Suomalaiset saavat ruuasta THL:n FinRavinto 2017 -tutkimuksen mukaan liikaa proteiinia, kun taas hiilihydraatin ja kuidun saanti on riittämätöntä.
Ravintoaineet, niiden saanti FinRavinto 2017 -tutkimuksen mukaan sekä mukanaolo MTK:n ravintoainetiheysindeksissä.
Uuteen laskelmaan on kriittisen palautteen myötä otettu kuitu mukaan ja huomioitu rasvahappojen saannin osalta myös rasvan laatu (kovat/pehmeät).
MTK:n viime viikolla julkistama laskelma vertaa siis viittä ostoskassia, joista neljä on muodostettu S-ryhmän ostosdatan ja viides ravitsemussuositusten perusteella. Kassien kooksi on vakiotu 15 kg, mutta niiden sisältämä energiamäärä vaihtelee huomattavasti, mikä tuntuu erikoiselta ratkaisulta.
Eri ruokavalioiden ilmastovaikutuksia on aiemmin tutkittu sekä kansainvälisesti (esim. Scarborough et al. 2014) sekä Suomessa, jossa Luke ja Suomen ympäristökeskus tuottivat valtioneuvoston selvitys- ja tutkimustoiminnan (VNTEAS) hankkeena, vuonna 2019 valmistuneen laajan aiheitta käsittelevän RuokaMinimi-tutkimuksen. Tutkimustietoa aiheesta siis on ja sen sanoma on jokseenkin yksiselitteinen. Kuten Luken vanhempi tutkija Juha-Matti Katajajuuri STT:n haastattelussa toteaa: kasvisruoka on yksiselitteisesti ilmastoystävällisin ravinnonlähde. Mitä uutta MTK:n selvitys kysymykseen siis tuo?
Senja Arffmanin mukaan tarkoituksena ei ole ollut vertailla ruokavalioita vaan ostoskäyttäytymistä, mutta tämä tuntuu selittelyltä, varsinkin kun koko tutkimuksen pihvi on ostoskassien sisällön suhteuttaminen ravitsemussuositusten ideaaliarvoihin. Vähintään tutkijan pitäisi pystyä perustelemaan, miksi hänen mentelmänsä tuottaa tieteellisen konsesuksen kanssa selvässä ristiriidassa olevia tuloksia. Tulokset pitäisi myös julkistaa niin, ettei tutkimuskohteesta jää epäselvyyttä.
Todellisuudessa kyse lienee pikemminkin siitä, että MTK haluaa eläintuottajien tukemiseksi hämmentää disinformaatiolla ruuan ympäristövaikutuksista käytävää keskustelua samaan tapaan kuin tupakkateollisuus aikanaan sotki keskustelua tupakan terveyshaitoista. Siksi pidän tarpeellisena nostaa esiin miten tarkoitushakuisella laskentamenetelmällä MTK:n kauppakassivertailu on toteutettu.
Käytetty laskutapa ei ilmene MTK:n omista materiaaleista, mutta Envitecpoliksen blogissa se kuvaillaan – ainakin jollain tarkkuudella.
Ymmärrän blogista löytyvän kuvailun perusteella menetelmän olevan seuraava:
Verrataan kunkin kassissa olevan ruoka-aineen jokaisen ravintotekijän määrää per 1 000 kcal kyseisen ravintotekijän ravitsemussuositusten mukaiseen minimiravintoaihetiheyteen per 1 000 kcal (Suomalaiset ravitsemussuositukset 2014, Liite 6, s. 51)
Jos ravintotekijän määrä ruoka-aineessa on vähintään ravitsemussuositusten mukaisen kynnysarvon verran, lisätään prosenttiluku (joka on aina vähintään 100 %) ”ravintoainetiheyspisteisiin”
Ongelmana vain on, että tällä tavoin lasketut ruokakassien pistemäärät ovat n. 50× suurempia kuin tutkimuksen julkistustilaisuuden esittelymateriaalien sivulla 7 kuvatut ravintotiheyspistemäärät!
Kokeilin miettiä muita mahdollisia tulkintoja blogissa kuvaillulle laskentamenetelmälle, mutta mikään keksimäni laskentatapa ei tuota julkistusmateriaalia vastaavia pisteitä, vaan kaikilla eri tavoilla lasketut pisteet ovat huomattavasti suurempia kuin esittelymateriaaleissa mainitut ravintotiheyspisteet.
Koska edellä kuvatulla tavalla lasketut pisteet ovat kuitenkin suunnilleen samassa suhteessa toisiinsa kuin selvityksen materiaaleissa ilmoitetut pisteluvut – tarkoittaen, että esimerkiksi alle 34-vuotiaiden kaupunkilaisten ostoskassin pisteet ovat suuruusluokkaa kaksinkertaiset yli 64-vuotiaiden maaseudulla asuvien ostoskassin pisteisiin – oletan, että selvityksessä käytetty laskentatapa on suunnilleen yllä kuvatun kaltainen ja tuo n. 50-kertainen ero johtuu jostakin pisteille laskemisen jälkeen tehdystä normalisoinnista, jota ei ole menetelmän kuvauksessa mainittu. Näin ollen oletan, että yllä kuvattu menetelmä tuottaa ainakin suhteellisesti oikean suuruisia lukemia, vaikka absoluuttiset pistemäärät poikkeavat huomattavasti ilmoitetuista. (Mikäli tämä oletus on väärä, myös osa kirjoituksen loppuosan johtopäätöksistä saattaa olla virheellisiä.)
Käytetyssä laskentatavassa on ainakin kaksi perustavanlaatuista ongelmaa:
Elintarvikkeen määrä ostoskassissa ei vaikuta mitenkään sen saamiin pisteisiin.
Menetelmä suosii elintarvikkeita, joissa on huomattavan suuria määriä yksittäisiä ravintoaineita monipuolisuuden kustannuksella ja ravintoaineen lisääminen parantaa aina tuloksia, vaikka sitä olisi kassissa entuudestaan jo riittävästi.
Koska vertailu perustuu ruoka-aineen ravintoainetiheyteen per 1 000 kcal, ei ole väliä onko sitä kassissa 50 g vai 5 kg – riittää että ruoka-aine on ylipäänsä mukana kassissa. Sen määrä vaikuttaa kuitenkin kassin ilmastopäästöihin, mikä antaa mahdollisuuden pelata luvuilla. Kassithan eivät perustu todellisiin ostoksiin, vaan ”eri ruoka-aineryhmien painottumiseen ostajaprofiileissa” ja ”profiilien suosituimpiin ruokavalintoihin ruoka-aineryhmittäin”. Tämä jättää liikkumavaraa kassin sisällön painottamiselle tarkoitushakuisesti.
(Jo vertailu kasvispainotteisen ja ravitsemussuositusten mukaisen kassin välillä perustuu tarkoitushakuisiin valintoihin, sillä kuten selvityksen taustamateriaaleissa todetaan myös alle 34-vuotiaiden kaupunkilaisten ostoksissa on todellisuudessa mukana paljon liha- ja maitotuotteita.)
Vaikuttaa tarkoitushakuiselta, että vaikka muiden kassien paino on 15 kg, ravitsemussuositusten mukaisen kassin sisältämien elintarvikkeiden kokonaispaino on vain 13,5 kg. Näin kassin ilmastopäästöt on saatu pienemmiksi ilman, että tämä vaikuttaisi ravitsemusarvoihin.
Vertailussa pisteitä saa korkeasta ravintoainetiheydestä, ei monipuolisuudesta. Elintarvike, jonka yhden ravintoaineen tiheys ylittää vertailuarvon moninkertaisesti tuottaa enemmän pisteitä kuin ruoka-aine, jossa monen tiheys jää täpärästi rajan alle. Esimerkiksi juustonaksujen ja perunalastujen ravintoainetiheys vastaa tällä laskutavalla ruisleipää ja vitaminoitu energiajuoma pieksee kalan ja lihan sekä monet vihannekset ja hedelmät. Kahvi ja aromisuola ovat varsinaisia superfoodeja.
Niinpä suunnilleen samaan ravintoainetiheyteen vertailussa mukana olleen lapsiperheen ostoskassin kanssa päästään esim. seuraavalla ”poikamiehen ostoskassilla”:
herkkusienipizza
soijanakki
tonnikalasäilyke
tumma makaroni
ranskanleipä
suklaa–mansikkamuro
suolapähkinä
perunalastu
juustonaksu
vähärasvainen kermaviili + dippijauhe
ketsuppi
hampurilaiskastike
soijakastike
sweet & sour -kastike
sipulirouhe
valkosipulimurska
aromisuola
energiapatukka
energiajuoma
kaakaojuoma
kahvi
I-olut
On selvää, että yllä kuvattu ruokakassi ei ole ravitsemuksellisesti laadukas. Se sisältää kuitenkin vain vähän eläintuotteita, joten mikäli kassille laskettaisiin myös ilmastopäästöt, se saattaisi saada suunnilleen yhtä hyvän ”CO2-ravintotiheysindeksin” kuin ravitsemussuositusten mukainen kassi.
Koska tutkimuksessa käytettyjä menetelmiä ei ole kuvattu läpinäkyvästi olen saattanut laskea edellä väärin. On kuitenkin selvää, että käytetty menetelmä on altis tietoiselle manipuloinnille ja vaikuttaa siltä, että sitä on myös harjoitettu halutun tuloksen saamiseksi.
MTK on lobbausjärjestö, joka puolustaa jäsentensä etuja tarvittaessa keinoja kaihtamatta (lain puitteissa tietenkin). Siksi heitä on mielestäni turha syyllistää tästä tutkimuksesta. Oma syyttävä sormeni osoittaa ennemminkin mediaan, joka uutisoi siitä kritiikittä. Kun etujärjestö julkaisee selvityksen, joka vaikuttaa haastavan koko vakiintuneen tieteellisen konsensuksen, olisi syytä muistaa Journalistin ohjeiden 12. kohta: ”Tietolähteisiin on suhtauduttava kriittisesti. Erityisen tärkeää se on kiistanalaisissa asioissa, koska tietolähteellä voi olla hyötymis- tai vahingoittamistarkoitus.” Toimittajien pitäisi yllättävän tutkimustuloksen kohdatessaan haastaa tiedontuottajaa enemmän. Miten tulokset on saatu? Miksi ne ovat ristiriidassa aiemman tiedon kanssa?
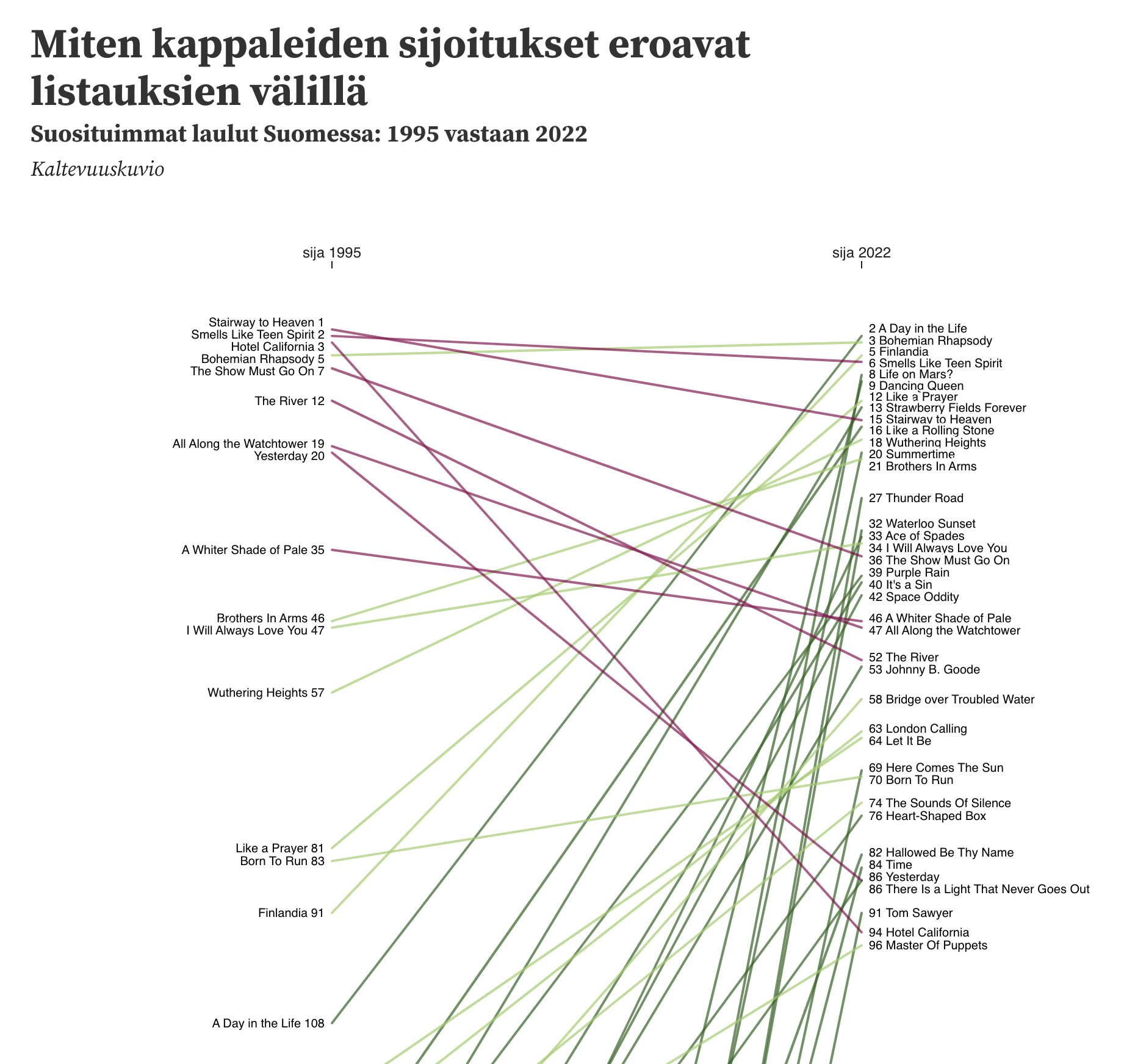
Ovatko ”maailman parhaimmat laulut” suomalaisten mielestä yhä samoja kuin 27 vuotta sitten? Kokeilin visualisointia Observablella ja testasin samalla ”fuzzy match” -toimintoa Pandas-kirjastossa. Aineistona oli Helsingin Sanomien koostama asiantuntijaraadin lista vuodelta 2022 sekä Wikipediassa tallennettu Radio Novan kuulijakyselynä rakennettu listaus vuodelta 1995:
Visualisointi rakennettu D3-kirjastolla Observablessa
Mikä ihmeen Observable?
Observable on Mike Bostockin ja Melody Meckfesselin perustama yritys ja verkkopohjainen ympäristö, jossa luodaan vuorovaikutteisia dokumentteja eli ”muistioita”, englanniksi notebookeja. Bostock tunnetaan suositun D3-JavaScript-kirjaston kehittäjänä, ja D3 onkin keskeinen osa Observablea. Muistio tai notebook on siis tiedosto, joka koostuu soluista. Solut ovat yksikköjä, pieniä laatikoita joihin voi kirjoittaa JavaScript-koodia, HTML:ää sekä tekstiä (jota voi muotoilla Markdown-merkintäkielellä). Ajatus on, että ympäristö auttaa yhdistämään analyysin, visualisoinnin ja julkaisemisen saumattomaksi ja helposti jaettavaksi kokonaisuudeksi.
Perinteisemmän ohjelmointiin verrattuna muistiossa sekä koodi että se mitä sen ajaminen tuottaa näkyy siis samassa dokumentissa. Observablessa jokaisen solun tulos näytetään sen yläpuolella:
Observablella on olemassa runsaasti tutoriaaleja sekä muistioina että videomuodossa ja niihin tutustuminen lienee paras tapa ymmärtää miten ympäristö toimii: https://observablehq.com/tutorials.
Keskeisimmät erot Jupyteriin ovat siinä, että Observablen solut ajetaan uudestaan automaattisesti, eikä solujen järjestyksellä ole väliä. Tämän takia funktiomäärittelyt voidaan sijoittaa ”piiloon” muistion loppuun, eikä tarvitse muistaa ajaa soluja uudelleen oikeassa järjestyksessä jos tekee muutoksia. Koodi ajetaan siis samalla tavalla kuin funktiot taulukkolaskentaohjemissa kuten Excelissä. Toimintatapaa selitetään tarkemmin tässä muistiossa.
Jokainen solu palauttaa myös ainoastaan yhden arvon – arvot solujen sisällä eivät siis lähtökohtaisesti ole muiden solujen käytettävissä, vaan ne pitää erikseen palauttaa. Toisin kuin Jupyterissa, Observablella ei ole erillistä ydintä eli kerneliä: koodi ajetaan selaimessa. Oletusarvoisesti Observablen muistiot siis asuvat tiedostoina Observablen palvelimella – mutta selaimesi ajaa niissä olevan koodin. Koodia voi myös tuoda vaivattomasti muistiosta eli notebookista toiseen ja erilaisia JavaScript-kirjastoja on helppo käyttää. Muistioita voi myös ”forkata”, eli kopioida uusiksi versioiksi.
Tieteentekijöille Observablen käyttökelpoisuutta voi rajoittaa se seikka, että esimerkiksi kaikille R– tai Python-kirjastoille ei välttämättä ole olemassa suoria tai ainakaan yhtä vakiintuneita ja dokumentoituneita JavaScript-pohjaisia vaihtoehtoja. Sen sijaan se voi olla oiva väline esimerkiksi prototyyppien luomiselle verkkokehittäjille ja datajournalisteille sekä algoritmisen taiteen tekijöille. Se voi myös olla varteenotettava julkaisualusta datajournalistisille projekteille.
Itse tein tähän raakadata datan käsittelyn pääosin Pandas-kirjaston avulla Jupyter-ympäristössä, sillä se on minulle vielä toistaiseksi tutumpi kuin Observable. ”Fuzzy matching” eli sumea vertailu oli helppoa käyttäen difflib-kirjastoa. Ohje löytyi luonnollisestikin StackOverflowista. Kahden DataFramen yhdistäminen indexin perusteella difflibin avulla näyttää tältä:
Tätä ohjetta muokkaamalla sain yhdistettyä kahden eri listan kappaleet nimen perusteella eri vuosilta siitä huolimatta, että niissä oli vaihtelevat kirjoitusasut. En säätänyt algoritmin tarkkuutta, joten se yhdisti aika reippaasti ihmisen näkökulmasta: Abban Don’t Shut Me Down yhdistyi esimerkiksi Pandoran kappaleeseen Don’t You Know. Koska lista tässä tapauksessa oli maltillisen kokoinen, niin oli helpompi siivota nämä käsin pois kuin säätää asetuksia (ja mahdollisesti jättää jokin kappale pois vahingossa!).
Observablen käyttö on tätä kirjoittaessa yksittäisille käyttäjille maksuton, ryhmälisenssit myydään kuukausihinnalla.
Sunnuntaina järjestettävien eduskuntavaalien tulosta on totuttuun tapaan spekuloitu ennakkoon ahkerasti. Ennustaminen on aina vaikeaa, erityisesti tulevaisuuden, mutta tällä kertaa vaalituloksen ennustaminen on tavallistakin hankalampaa.
Puolueiden kannatusta mittaavien mielipidekyselyiden tulokset antavat toki jonkinlaista osviittaa mahdollisesta vaalituloksesta. Yhdistämällä viimeisimpien Ylen, Helsingin Sanomien ja Alma Median gallupien tulokset saadaan seuraavanlainen tulos:
Kannatus
Virhemarginaali
SDP
19,4 %
±1,3 %
kokoomus
16,8 %
±1,2 %
PS
14,9 %
±1,2 %
keskusta
14,5 %
±1,2 %
vihreät
12,5 %
±1,1 %
vasemmistoliitto
9,1 %
±0,9 %
RKP
4,4 %
±0,7 %
KD
4,2 %
±0,7 %
siniset
1,3 %
±0,4 %
muut
2,9 %
±0,6 %
(Mielipidemittausten tulosten yhdistämistä ja puoluekohtaisen virhemarginaalin laskemista käsitellään lähemmin tässä artikkelissa.)
Vaikka tulokseen liittyy epävarmuustekijöitä, uskon, että lopullinen valtakunnallinen tulos on luultavasti melko lähellä tätä.
Eduskunnan paikkajakoa ei kuitenkaan ratkaise puolueiden valtakunnallinen äänisaalis, vaan se, kuinka paljon ääniä niille kussakin vaalipiirissä kertyy. Tämän ennustaminen on aina vaikeaa, mutta erityisen hankalaa näissä vaaleissa, sillä mukana on suuri määrä uusia tai sitten viime vaalien kannatustaan kasvattaneita pienpuolueita, joiden vaikutusta on hyvin vaikea arvioida. Erityisen hankalaksi asian tekee se, että moni nykyinen kansanedustaja, mukana muutamia viime vaalien ääniharaviakin, on näissä vaaleissa valtakunnallisesti alle parin prosentin kannatuksen kellottavan puolueen ehdokkaana.
Yle ja Vihreä Lanka ovat molemmat laatineet omat ennusteensa paikkajaosta, mutta kumpikaan niistä ei ole metodologisesti tyydyttävä. Yle ei avaa lainkaan esimerkiksi sitä, millä perusteella kannatus on jyvitetty vaalipiireittäin ja miten puoluekentän muutokset on ennusteessa huomioitu – vai onko mitenkään. Vihreä Lanka on kiitettävän avoin käyttämästään mallista, mutta kuvauksen perusteella mallissa on ilmeisiä katvealueita.
Päätin yrittää itse kokeilla mallinnusta, joka huomioisi puolueiden valtakunnallisten kannatuslukujen lisäksi Turun Sanomien, Satakunnan Kansan, Kymen Sanomien, Karjalaisen, Savon Sanomien, Kalevan ja Lapin Kansan teettämät vaalipiirikohtaiset mielipidemittaukset ja vaaliliitot, ja ottaisi jollain tapaa huomioon myös kansanedustajien puolueenvaihdokset vaalikauden aikana.
Tehtävä osoittautui hankalaksi. Suurin ongelma on datan puute. Vaalipiirikohtaisia mielipidemittauksia ei ole tehty kaikissa vaalipiireissä, ja useimmissa paikallisissa gallupeissa otoskoko on joko naurettavan pieni tai sitä ei ole edes ilmoitettu.
Valtakunnallisen kannatuksen jyvittämisessä vaalipiireihin hyödynsin tietoa kansanedustajien vuoden 2015 vaaleissa saamista henkilökohtaisista äänimääristä, niin että esimerkiksi Harry Harkimon Uudellamaalla saama äänimäärä vähennettiin Uudenmaan kokoomuksen potista ja lisättiin Liike Nytille. Samoin toimittiin sinisen eduskuntaryhmän kansanedustajien kohdalla, joiden saamat äänet vähennettiin perussuomalaisten potista. Paavo Väyrynen on sen sijaan hankalampi tapaus, sillä hän on vaihtanut paitsi puoluetta, myös vaalipiiriä. Tein lopulta Lapin Kansan mielipidemittauksen perusteella – se ei ennusta järin suurta kannatusta eduskunnan ulkopuolisille puolueille Lapin vaalipiirissä – sellaisen melko mielivaltaisen päätöksen, että jyvitin vain kolmasosan Väyrysen saamista äänistä Seitsemän Tähden Liikkeelle.
Hyvin äkkiä huomasin, että kun dataa on vähän, erilaisia painokertoimia ja oletuksia tarvitaan paljon, eikä niille löydy kovin hyviä perusteluita, vaan ne jäävät tyypillisesti aika mielivaltaisiksi. Miten esimerkiksi pitäisi painottaa vaalipiirikohtaista mielipidemittauksen tulosta suhteessa valtakunnalliseen? (Pelkkiin vaalipiirikohtaisiin kyselyihin en halunnut luottaa silloinkaan kun sellainen oli saatavilla, sillä niiden otoskoot olivat yleensä varsin pieniä, ja monet on julkaistu ennen perussuomalaisten viimeaikaista gallupnousua.) Päädyin käyttämään paikallisen gallupin vastaajaluvun parina lukua, joka on muodostettu jakamalla valtakunnallisten gallupien yhteenlaskettu vastaajamäärä (3 554) kahdella sadalla ja kertomalla tämä sitten vaalipiirin kansanedustajapaikkojen määrällä. Esimerkiksi Oulun vaalipiirissä painotin siis Kalevan gallupia, jossa kantansa ilmaisi 368 vastaajaa suhdeluvulla 368 / 320, jossa 320 on saatu laskukaavalla 3 554 ÷ 200 × 18.
Näillä oletuksilla paikkaennuste on seuraava:
SDP
45
(+10)
kokoomus
35
(–3)
PS
32
(+15)
keskusta
32
(–16)
vihreät
24
(+9)
vasemmistoliitto
16
(+4)
RKP (sis. Ahvenanmaan edustajan)
9
(–1)
KD
6
(+1)
Liike Nyt
1
(–1)
siniset
0
(–17)
muut
0
(–1)
(Suluissa muutos suhteessa tämänhetkisen eduskunnan kokoonpanoon.)
Kuinka varma tämä tulos on? Hyvin epävarma.
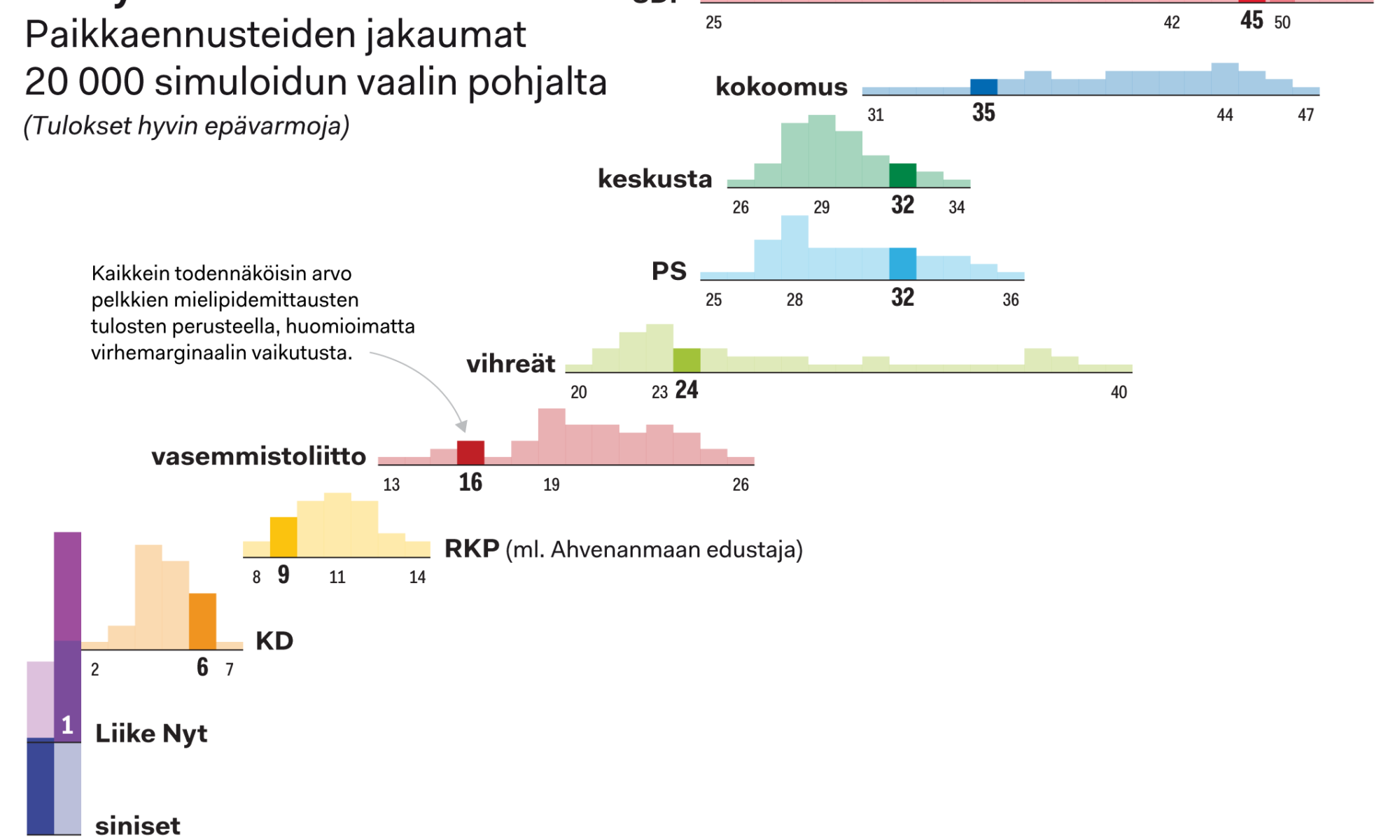
Kokeilin simuloida vaalitulosta siten, että kunkin puolueen äänimäärä vaihtelisi vaihtelisi hieman lasketun keskiennusteen ympärillä. Tässä hankalaksi kysymykseksi muodostui se, mikä olisi oikea tapa määritellä satunnaismuuttujan hajonta, kun data ei ole yhteismitallista eikä kaikilta osin kovin laadukasta. Menemättä yksityiskohtiin, kokeilin runsaasti kaikenlaisia vaihtoehtoja saavuttamatta kovin tyydyttävää tulosta, tai kykenemättä esittämään hyviä perusteluita sille, miksi juuri tämä tai tuo painotus tai kerroin olisi sen perustellumpi kuin joku toinen.
Ohessa esimerkki yhden simulaation tuloksista. Tässä ”vaali” siis ajettiin 20 000 kertaa läpi hieman satunnaisesti varioiden kunkin puolueen kussakin vaalipiirissä saamaa äänimäärää:
Kuten kuvasta näkyy, hajonta on useimpien puolueiden osalta kuin haulikolla ammuttu. Kiinnostavasti juuri minkään puolueen kohdalla aiemmin laskettu todennäköisin arvo ei ole hajonnan keskellä, eivätkä useimmat käppyrät muutenkaan vaikuta normaalisti jakautuneilta. Kyse voi toki olla virheestä hätäisesti kyhätyssä koodissani – tämä ei yllättäisi minua lainkaan –, mutta datan lähempi tarkastelu viittaa toiseenkin mahdolliseen selitykseen: todella monessa vaalipiirissä viimeisestä 1–2 paikasta tullaan käytössä olevien lukujen valossa käymään todella kova kisa.
Oman analyysini pohjalta uskallan veikata sunnuntain vaalituloksesta vain, että se tulee sisältämään yllätyksiä. Millaisia, se jää nähtäväksi. Odotus ei onneksi ole enää pitkä.
Artikkelia muokattu 13.4.2019 klo 12:54: Korjattu ennustettujen kansanedustajapaikkojen määrää koskevassa taulukossa virheelliset muutos nykyiseen eduskunnan kokoonpanon -tiedot.
We teach the course “Information Design II” as a part of the the Information Design track of the Master studies in Visual Communication Design at Aalto university. This year we gave our students the following open brief:
Pick a subject of interest and gather data about it. You may also choose to continue your project from Information Design I.
Study your subject carefully and develop a way to explain and represent it visually. You can focus on a particular aspect or strive to give a broader overview of the topic in question. Your work should include several graphics and represent both qualitative and quantitative (numerical) information.
Here’s a selection of interesting projects that were created during the course. Click images to enlarge.
Yentsen Liu: StatFin Database interface redesign
Yentsen did a thorough review of Statistics Finland’s PX-Web database interface and worked on a suggestion for a more usable and contemporary redesign. You can read a comprehensive explanation of the project here: blog.yentsenliu.com/redesign_statfin
Helén Marton: (Mis)informed
Helén developed a concept for an online platform called (Mis)Informed. The purpose for the site is to combat misinformation by:
– hosting a public library of bad, misleading or straight-up deceiving information graphics/visualizations
– by offering educational material to assist in developing a critical eye when viewing graphics.
Helén is currently looking for collaborators to take this project further. Contact her via e-mail: mail{at}helenmarton.com
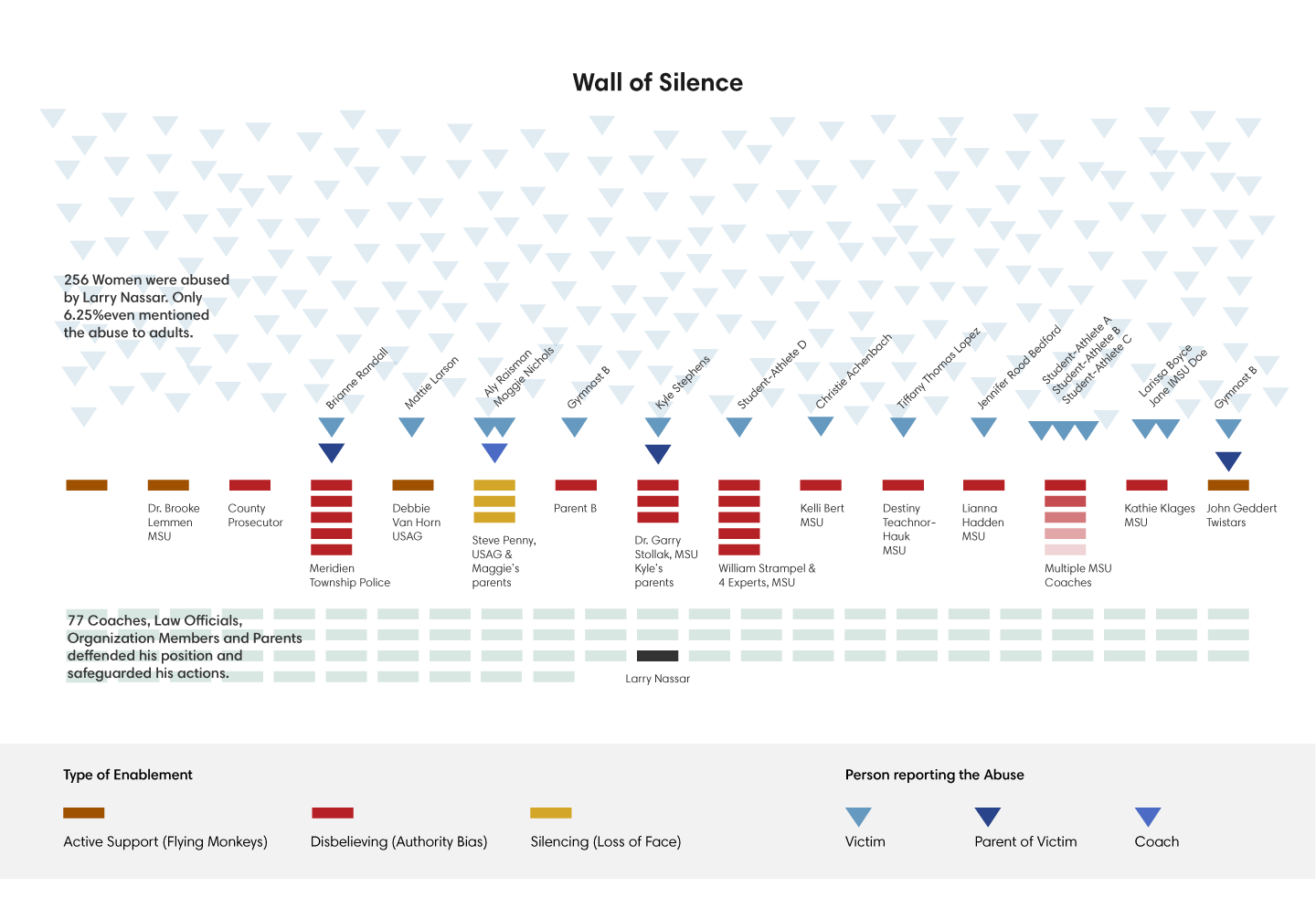
Adina Renner: Flying Monkeys and a Wall of Silence
Adina wrote and designed a sketch for a thoughtful web article about how young athletes were systematically abused by the physician Larry Nassar. The goal was to make visible the web of connections, that made the abuse possible and allowed it to continue for years.
Lilla Tóth: When Hollywood says ‘I love you’
Lilla used a collection of Hollywood movie scripts to investigate when – and how many times – male and female actors utter the words ‘I love you’ in different films.
Lilla’s portfolio is at behance.net/lillatoth
Liam Turner: Tracing the origins of California city names
Liam created an elegant map that looks at the historical and thematical origins of city names in California.
Liam’s portfolio is at califjordia.com
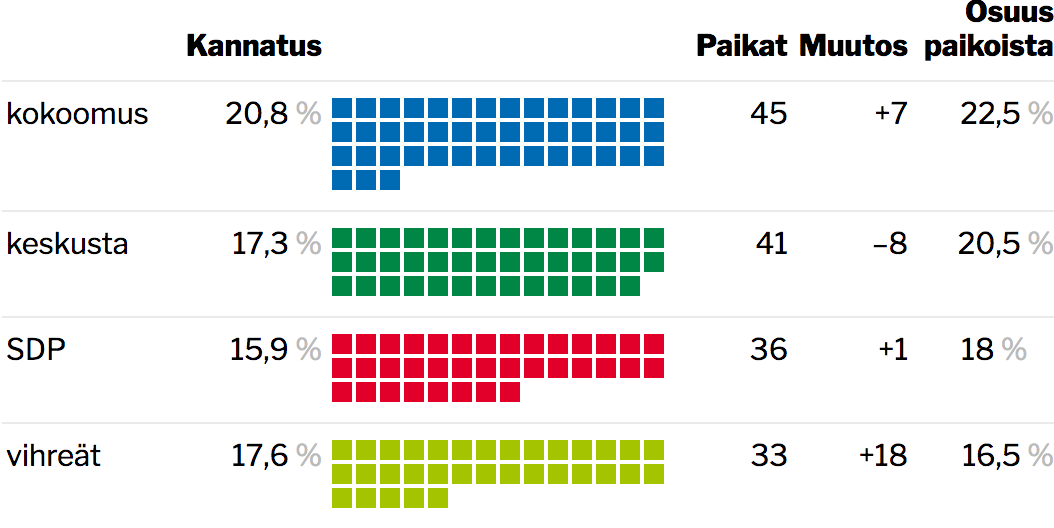
Eilisen iso uutinen Suomen politiikassa oli Ylen julkaisema kannatusmittaus, joka nosti vihreät jo maan toiseksi suosituimmaksi puolueeksi huimalla 17,6 prosentin kannatuksella. On monia hyviä syitä olettaa, että puolueen suosio tulee seuraavassa mittauksessa olemaan tätä pienempi, eikä mielipidemittaus kerro välttämättä paljoakaan lopullisesta vaalituloksesta – ei vähiten siksi, että seuraaviin eduskuntavaaleihin on aikaa vielä kaksi vuotta (mikäli sitä ennen ei jouduta ennenaikaisiin vaaleihin) . Tulos on silti niin poikkeuksellinen, että on herkullista leikitellä hetki mitä jos -tyyppisellä pohdiskelulla ja kysyä, miten näiden lukujen mukainen vaalitulos kääntyisi eduskuntapaikoiksi.
Missään maailman maassa puolueiden parlamenttiin saamien paikkojen määrä ei perustu täysin suoraan saatujen äänten määrään – siis niin, että vaikkapa 10 prosenttia äänistä kerännyt puolue saisi aina 10 prosenttia parlamenttipaikoista. Tähän on erilaisia syitä. Joissain maissa suurimpien puolueiden asemaa on tietoisesti pönkitetty äänikynnyksen tai vaalien voittajalle jaettavien ”bonuspaikkojen” muodossa. Myös halu turvata maan eri osien tasapuolinen edustus parlamentissa vaalipiirien avulla aiheuttaa tällaista epäsuhtaa ääni- ja paikkamäärien välille. Mm. angloamerikkalaisissa maissa yleisesti käytetty enemmistövaalitapa voi johtaa todella räikeisiinkin poikkeamiin suhteellisuudessa. Kansainvälisessä vertailussa Suomen vaalijärjestelmä on toteutuneiden vaalitulosten valossa kohtuullisen edustava, mutta esimerkiksi Tanskassa, Israelissa ja Uudessa-Seelannissa ääni- ja paikkamäärien suhteellisuus toteutuu vielä paremmin.
Laskin, miten Ylen mielipidemittauksen mukainen vaalitulos kääntyisi eduskuntapaikoiksi, jos kunkin puolueen saamat äänet jakautuisivat eri vaalipiireihin samassa suhteessa kuin vuoden 2015 eduskuntavaaleissa. Tämä tarkoittaisi esimerkiksi, että vihreiden koko maassa saamista äänistä noin 27 % annettaisiin Helsingissä, kun taas RKP:n äänistä 35 % tulisi Vaasan vaalipiiristä. Lisäksi oletan yksinkertaisuuden vuoksi, että yksikään tällä hetkellä eduskunnan ulkopuolella oleva puolue ei saisi haalittua riittävästi ääniä yhdenkään ehdokkaan läpimenoon.
Lopputulos ei näytä optimaaliselta vihreiden kannalta, vaikka toki näillä luvuilla puolue olisi vaalien suurin voittaja. 17,6 % äänistä toisi vihreille vain 16,5 % paikoista, ja maan toiseksi suosituin puolue jäisi kansanedustajapaikoissa vasta neljännelle sijalle johtuen kannatuksen epäedullisesta jakautumisesta.
Vaalipiirijako näyttää näillä luvuilla suosivan erityisesti keskustaa ja SDP:tä, joista kumpikin haalisi selvästi ääniosuuttaan suuremman määrän kansanedustajapaikkoja. Myös kokoomuksen paikkamäärä on suhteellisesti suurempi kuin ääniosuus. Kaikki pienemmät puolueet saisivat taas hieman ääniosuuttaan pienemmän osuuden paikoista. (RKP:n hieman tutkimuksessa mitattua ääniosuutta suurempi edustajanpaikkojen määrä johtuu siitä, että Ahvenanmaa eli ole mukana mielipidemittauksessa. Maakunnan edustaja istuu kuitenkin perinteisesti aina RKP:n eduskuntaryhmässä, eli puolue saa tavallaan yhden lisäpaikan.)
Suurten ja pienten puolueiden suhteellinen menestys selittyy pitkälti suomalaisissa vaaleissa käytetyllä laskentatavalla, joka normaalisti suosii suuria puolueita – vihreiden suurella kannatuksella kellottama matala edustajanpaikkojen määrä on tässä mielessä hyvin poikkeuksellinen.
Alla vielä vaalipiirikohtaiset tulokset. Vaikka on epätodennäköistä, että lopullinen vaalitulos olisi kovin täsmällisesti lähellä Ylen eilisen mielipidemittauksen tulosta, on taulukosta silti helppo huomata, että viherjytkyn materialisoituminen vaatisi vihreiden tuloksen parantumista varsinkin suurten kaupunkien ulkopuolella.
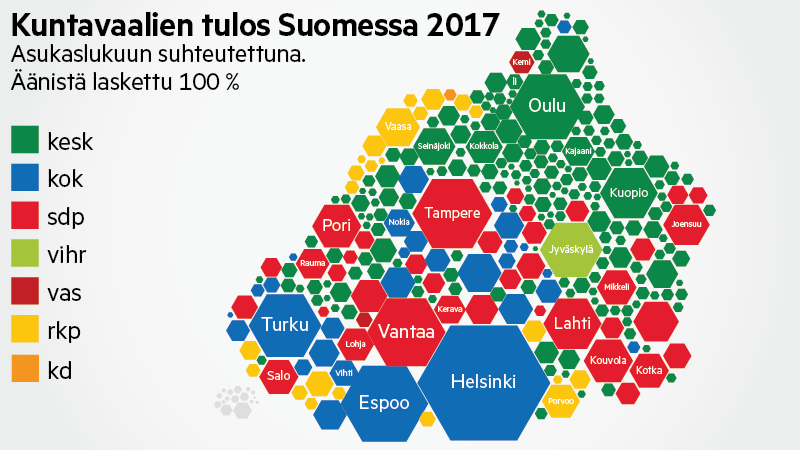
Lisäys 18.8. klo 14:51: Sosiaalisen median puolella esitettiin hyvä kysymys: miltä tulos näyttäisi, jos eri puolueiden saamien äänten alueellinen jakautuminen muistuttaisi pikemminkin kuntavaalien 2017 kuin eduskuntavaalien 2015 tulosta. Alla oleva taulukko näyttää paikkaennusteen kunnallisvaalien tuloksen pohjalta.
Tulos näyttää vihreiden kannalta paremmalta kuin ylempää löytyvä, eduskuntavaalien tulosta pohjana käyttävä ennuste. Keskusta ja SDP pärjäävät edelleen suhteellisesti paremmin, mutta asetelma on vihreille hieman vähemmän epäedullinen, ja näillä luvuilla vihreät nousisi eduskunnan kolmanneksi suurimmaksi puolueeksi. Voidaan siis todeta, että vihreät on jo kevään kuntavaaleissa onnistunut levittämään kannatustaan maantieteellisesti laajemmalle alueelle viime eduskuntavaaleihin nähden. Jos suunta jatkuu samana, tämä lupaa hyvää vihreiden paikkamäärälle seuraavissa vaaleissa.
Muidenkin puolueiden paikkamäärissä on pieniä muutoksia. Erityisen mielenkiintoinen yksityiskohta on, että kristillisdemokraattien paikkamäärä putoaisi puoleen eduskuntavaaleihin pohjautuvaan skenaarioon verrattuna.
Ilta-Sanomatkirjoitti karttaprojektioista ja The True Size -sivustosta, jonka avulla voi vertailla visuaalisesti maailman valtioiden pinta-aloja. Jutun pihvi on, että kaikille tuttu Mercatorin projektio antaa harhaanjohtavan kuvan maailmasta, koska se näyttää mm. Euroopan ja Pohjois-Amerikan paljon todellista kokoaan suurempina.
Aihe on tärkeä ja kiinnostava, mutta IS:n juttu vahvistaa jälleen kerran lähes kaikkia kartografiaan perehtyneitä suunnattomasti ärsyttävää myyttiä, että vasta Arno Petersin 1960- ja 70-lukujen taitteessa ”keksimä” Gall-Peters-projektio olisi ensi kertaa antanut totuudenmukaisen kuvan siitä, miltä maailma ”oikeasti” näyttää. Tosiasiassa oikeapintaisia, siis maantieteellisten alueiden pinta-alojen suhteet oikein näyttäviä karttoja on tehty jo vuosisatoja – jopa ennen kuin Gerardus Mercator julkisti keksimäänsä karttaprojektiota hyödyntävän maailmankartan vuonna 1569. Kaiken lisäksi Gall-Peters on nykyisin tunnetuista oikeapintaisista projektioista selvästi huonommasta päästä.
Mercatorilla on käyttökohteensa
Kolmiulotteisen maapallon pintaa ei ole mahdollista esittää kaksiulotteisesti paperilla tai tietokoneen näytöllä ilman, että lopputulos vääristäisi maantieteellistä todellisuutta tavalla tai toisella (ks. tarkemmin esim. Koponen, Hildén & Vapaasalo 2016. Tieto näkyväksi, s. 180–181). Se, millaiset vääristymät ovat ongelmallisia ja mitkä voidaan hyväksyä riippuu suuresti kartan käyttökohteesta. Kuten Vox.comin julkaisema erinomainen selitysvideo hyvin osoittaa, ei ole sattumaa, että Mercatorin projektiosta on tullut niin suosittu. Ennen satelliittipaikannuksen yleistymistä Mercatorin projektioon tehdyt kartat olivat korvaamaton apuväline merenkulkijoille, ja esimerkiksi suomalaiset merikartat tehdään edelleen Mercator-projektioon. Myös pienten alueiden, kuten yksittäisen kaupungin kuvaamiseen Mercator sopii mainiosti.
Ongelmia tulee, kun Mercatorin projektiota käytetään pinta-alaltaan kohtalaisen suurta aluetta kuten Suomea kuvaavissa kartoissa. Projektio vääristää alueiden pinta-aloja sitä enemmän, mitä kauempana päiväntasaajasta ollaan ja vääristymän suuruus kasvaa eksponentiaalisesti. Niinpä Suomea kuvaavassa Mercator-projektiota käyttävässä kartassa Lappi näyttää kohtuuttoman suurelta eteläiseen Suomeen verrattuna. Maailmankartoissa ongelma on luonnollisesti vieläkin pahempi.
Yksittäisten maiden ja maanosien kuvaamiseen hyvin sopivia projektioita on kehitetty vuosisatojen mittaan runsaasti (ks. esim. Tieto näkyväksi, s. 345–347). Suomalaissa kartoissa käytetään yleensä jotain Mercatorin poikittaissuuntaista muunnosta, uusissa kartoissa tavallisimmin ETRS-TM35FIN-projektiota (s. 347–348). Maailmankartat ovat kuitenkin hankalampi tapaus ja kaikki tarjolla olevat vaihtoehdot ovat jollain tavalla puutteellisia. Mercatorin ongelma on se, että se vääristää alueiden pinta-aloja, kun taas oikeapintaiset projektiot kuten Gall-Peters vääristävät niiden muotoja.
Karttaprojektioiden aiheuttamaa vääristymää voidaan havainnollistaa nk. Tissot’n indikaattoreilla. Ne ovat kartalle piirrettyjä soikioita, jotka kuvaavat karttaprojektion aiheuttamaa vääristymää. Teoreettisessa täydellisessä karttaprojektiossa indikaattorit olisivat kaikki samankokoisia ympyröitä, jotka asettuisivat kartalle tasaisin välein suoriin riveihin. Koska tällaista karttaprojektiota ei ole olemassa, soikioiden muodot, pinta-ala ja/tai sijainti poikkeavat aina tästä ideaalista ja niiden avulla eri projektioiden aiheuttamia vääristymiä voi vertailla.
(Alla olevat kuvat ovat mainiolta Map-projections.net-sivulta, jossa karttaprojektioita voi helposti vertailla toisiinsa.)
Mercatorin projektiossa soikiot säilyvät ympyröinä, mutta niiden pinta-ala vaihtelee suuresti.
Gall-Petersin projektiossa taas soikioiden pinta-alat pysyvät samoina, muta niiden muodot ovat pahasti vääristyneitä. Sama ongelma koskee periaatteessa kaikkia oikeapintaisia projektioita, mutta on olemassa useita vaihtoehtoja, joissa vääristymä on pienempi kuin Gall-Petersissä.
Gall-Petersin suosio perustuu lobbaukseen, ei kartografisiin ansioihin
Gall-Petersin nousu nykyiseen asemaansa liittyy enemmän taitavaan lobbaukseen kuin projektion kartografisiin ansioihin. Saksalainen elokuvaohjaaja Arno Peters julkaisi vuonna 1973 itse kehittämänsä ”uudenlaisen” maailmankartan, jonka hän väitti ensi kertaa kuvaavan maailman sellaisena kuin se on, ilman mitään vääristymiä. Nämä väitteet eivät pidä paikkaansa. Täysin vääristämätöntä projektiota ei ole mahdollista kehittää, eikä varsinkaan Petersin projektio sellainen ole. Oikeapintaisia, alueiden pinta-alat oikein näyttäviä projektioita taas on käytetty satoja vuosia ja keskustelua Mercatorin aiheuttamasta vääristymästä oli kartografian piirissä käyty pitkälti yli sata ellei useita satoja vuosia siinä vaiheessa kun Peters toi oman karttansa suurieleisesti julkisuuteen. Esimerkiksi nykyisin Bonnen projektiona tunnettu oikeapintainen projektio, joka tuottaa sydämenmuotoisen maailmankartan on keksitty jo vuonna 1511. Peters ei edes keksinyt käyttämäänsä projektiota ensimmäisenä, vaan skotlantilainen James Gall oli keksinyt täsmälleen saman projektion jo vuonna 1855 (siitä nykyisin käytetty Gall-Peters-nimitys).
Kaiken lisäksi Peters-projektio ei ole lähellekään paras oikeapintainen projektio koko maapallon kuvaamiseen. Esimerkiksi vuonna 1906 kehitetty Eckert IV soveltuu tarkoitukseen paremmin ja oli yleisessä käytössä jo vuosikymmeniä ennen kuin Peters alkoi rummutaa ”keksimänsä” projektion erinomaisuutta. Vuonna 1973 julkistettiin myös Toblerin oikeapintainen projektio, joka aiheuttaa Tissot’n indikaattoreihin vieläkin vähemmän vääristymiä kuin Eckert.
Oikeapintainen Eckert IV -projektio
Oikeapintainen Toblerin hyperelliptinen projektio
Peters ei ollut ensimmäinen, joka yritti suistaa Mercatorin projektion sen kiistatta ansiottomasta asemasta maailmankarttojen perusvaihtoehtona. Hän onnistui paremmin kuin lukuisat edeltäjänsä ennen kaikkea siksi, että hän suuntasi lobbaustyönsä karttojen tekijöiden ja julkaisijoiden sijaan poliittisiin ja yhteiskunnallisiin toimijoihin ja onnistui määrittelemään ”keksintöönsä” kriittisesti suhtautuvat ammattilaiset eurosentrisiksi imperialisteiksi.
On surullista, että Petersin kartografisesti heikkotasoinen projektio nauttii edelleenkin mainetta ainoana Mercatorin haastajana, vaikka parempia vaihtoehtoja olisi tarjolla runsaasti. Edellä mainittujen oikeapintaisten vaihtoehtojen lisäksi voisi mainita myös ns. kompromissiprojektiot kuten Robinson ja Winkel-Tripel, jotka eivät pyri pääsemään täysin eroon vääristymissä sen enempää alueiden muodoissa kuin pinta-aloissakaan vaan hakemaan hyvän kompromissin, jossa mikään kartan osatekijöiistä ei vääristy liian pahoin.
Robinsonin projektio
Winkel-Tripel (W3) -projektio
On epäilemättä totta, että Mercatorin projektion vuosisatoja jatkunut dominanssi on vääristänyt kuvaamme ”etelän” ja ”pohjoisen” keskinäisestä maantieteellisestä painoarvosta. Ilta-Sanomienkin esiin nostamat esimerkit ovat kiinnostavia ja merkityksellisiä. Voi kuitenkin kysyä, onko pinta-ala silti lopultakaan se tekijä, joka parhaiten kuvaa valtion paikkaa maailmassa. Mauritanian pinta-ala on yli miljoona neliökilometriä, kun taas asukasluvultaan suurempi Singapore mahtuu reilun 700:n neliökilometrin alueelle. Sitä, että Mauritania saa kartassa kuin kartassa selvästi Singaporea suuremman visuaalisen painoarvon on vaikea karttaprojektiota vaihtamalla korjata.
Yhtenä ratkaisuna on käyttää kartan sijaan kartogrammia, jossa alueiden pinta-alat eivät perustu niiden todelliseen maantieteelliseen pinta-alaan vaan jonkin muun muuttujan, vaikkapa asukasluvun saamaan arvoon. Juuri tällä tavoin ratkaisimme itse äskettäisten kuntavaalien tuloksen kuvaamisen Aamulehdelle tekemässämme visualisoinnissa. Verrattuna vaalituloksen esittämiseen perinteisellä koropleettikartalla kartogrammi näyttää paremmin suurissa kaupungeissa hyvin menestyneiden kokoomuksen ja SDP:n suosion, kun perinteinen kartta ylikorostaa maaseudulla hyvin pärjäävän keskustan menestystä.
Joissain tapauksissa oikea karttaprojektio on siis ei karttaprojektiota laisinkaan. Mutta silloinkin kun kartta pidetään karttana, on projektioksi lähes aina tarjolla parempiakin vaihtoehtoja kuin Gall-Peters.
Two somewhat intertwining themes in many of the presentations at this year’s Malofiej conference (and last year as well) were what role interactivity and storytelling should play in data visualization. I think these two issues are related, and both of them are extremely important for our profession.
New York Times’ Archie Tse memorably told the conference (in 2016) that “readers just want to scroll” and that “if you make the reader click or do anything other than scroll, something spectacular has to happen.” That is, most of the visitors on a newspaper’s site don’t deeply interact with the graphics on the site, but instead prefer to just scroll and treat the interactive visualizations as static pictures.
Gregor Aisch published today a blog post titled “In defense of interactive graphics” which adds more shades of gray. I found this a particularly salient point: “– – you should not hideimportantcontent behind interactions. If some information is crucial, don’t make the user click or hover to see it – –. But not everything is crucial and 15% of readers isn’t nobody.” Another good point he makes is that letting the readers explore the data in detail helps spot mistakes and correct them.
Not all users and all use cases are as important! A sizeable part of my own work consists of doing interactive visualizations for public sector clients. Although the broadly defined target audience might be “anyone interested in the issue” very often there is a much, much smaller core audience, sometimes only a handful of people, whose needs are very different from a random visitor. These might be e.g. MPs who write legislation on the issue my client has a stake in, or experts in the subject matter working in a different arm of government. Such users are often much more invested in the issue to begin with, more knowledgeable on the topic, and more willing to spend time exploring a dataset. These past two days we heard of many examples of projects which may not have been huge hits with readers, but which helped journalists working within the newsroom to find stories. All these are examples of cases where you shouldn’t decide whether the graphic was succesful based only on how the 85% or 99% or users interacted (or didn’t) with it, but also take into account that some users are more valuable to you than others.
This brings us to the issue of storytelling. Jon Schwabish’s presentation discussed the topic at length yesterday, and in response to Jon’s thoughts Chad Skelton made the point in his blog that a literary story is different from a news story. I think this is true and important, but I would still argue a news story is called a “story” for a reason.
A story is defined in the dictionary as “an account of imaginary or real people and events told for entertainment”, “a piece of gossip; a rumour” – or even “a false statement; a lie”. (In a Finnish newsroom, likewise, a news story is called juttu; literally an anecdote, a yarn, even a joke.) The common theme here is that “a story” includes at least a somewhat subjective point of view, and a narrative arc, with which the writer or speaker ties a bunch of disparate facts together as a coherent explanation of a part of the world, whether or not that explanation is true. (Nathaniel Lash also touched on this issue in his presentation today.) A table of numbers is not a story (though a data journalist might see a story in that table), nor should an entry in a dictionary or encyclopedia be.
I found Anna Flagg’s presentation today extremely relevant for very many reasons, but one issue she discussed I want to specifically mention here was the question of perceived bias in journalism and how to combat that perception. She mentioned a survey according to which in the U.S., a whopping 71% of Trump supporters and even 50% of Clinton supporters wanted the media to report just the facts without including any interpretation their own. As professionals, we understand that, if taken literally, such reporting would probably not be possible and certainly not very useful. Nevertheless, these numbers are indicative of mistrust in the capacity and willingness of the media to report the facts fairly.
I would argue that part of the problem here is that we think of what we are doing as storytelling. A story is a structure which helps to connect disparate pieces of information (factual or not) into a coherent whole, to better understand and remember it. But what if those pieces, even if true, do not objectively fit into a coherent whole? How do we guard against the temptation of seeing a story where there isn’t one in reality? The journalistic code of ethics helps in weeding out intentionally misleading and plain sloppy reporting. I’m not sure it helps as much when the problem is journalists seducing themselves with their own stories.
This brings us back to the issue of interactivity. A non-interactive story is just that, a story – a necessarily somewhat subjective narrative arc tying up the facts into a coherent whole. Such a story can be informative and useful, but it is not transparent.
To add transparency to a data-driven story, add interactivity. Instead of showing just the portion of the data the journalist thinks is most relevant for the readers, let them explore the rest as well – if they so prefer. It seems most readers won’t take up the offer; despite saying they want just the facts without interpretation, based on New York Times’ experience most people seem to prefer the journalist’s interpretation of the data to exploring it on their own. But the minority who is interested in and willing to explore the data exists. We should cater to them as well as the majority.
Not only to give them an engaging experience and a better understanding of the world, but also to keep ourselves honest.


























{kind=link}